
因为在一个篇幅里面写完就太长了,太影响阅读,所以就分成了两部分,这里接上一篇的内容。
四、模型及预处理器
对于ControlNet模型来说,预处理器不是必须的,但我们还是要了解每个模型的预处理器是什么。
1、canny 边缘检测
canny 边缘检测模型类似于 lineart 线稿模型,对应的预处理器为 canny ,可以将图片变为线稿,然后再根据模型以及提示词对图片重新上色绘制,但是在细节方面的表现会比较差。

2、depth 深度图
深度图 depth 模型有 3 个对应的预处理器,分别是 leres / midas / zoe ,可以将原图转换为只有黑白灰的深度图像,越靠近摄像机的物体就越白,越远离摄像机的物体就越黑,这 3 个预处理器对应的效果如下。

从上图对比可以看出,leres 预处理器算出的深度图比较浅,前景跟背景的区分不是很明显;midas 的效果就类似于之前 1.0 版本的效果,前景跟背景的过渡比较生硬,是速度最快的深度图处理方法;而 zoe 的效果看起来就舒服很多,前景跟背景的过度比较柔和,从前景到背景可以看出有显明的纵深关系,但该处理方法所需的时间也会长很多。
3、inpaint 修复
根据官方的介绍,inpaint 修复模型使用 50% 的随机掩码和 50% 的随机光流遮挡掩码进行训练,这意味着该模型不仅支持图像修复,还可以处理视频光流扭曲。该修复模型有点类似于图生图中的局部重绘功能。

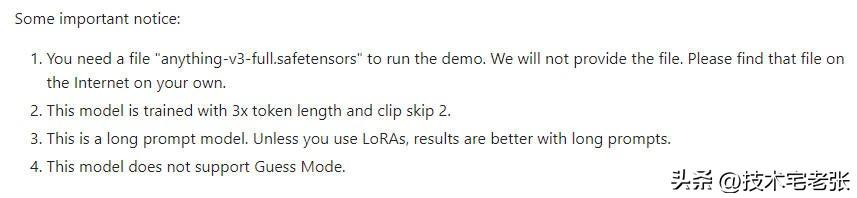
4、lineart_anime 动漫线稿(不支持猜测模式)
动漫线稿模型,可以根据线稿生成特定风格的图像,对应的预处理器为 lineart_anime,该模型及预处理器主要用于处理动漫类图像,相比于写实线稿,其在动漫图像上的表现会更好。
根据官方的说明,如果想要用这个模型来作演示,那基础大模型要选 anything-v3-full这个模型,在不使用 lora 模型的情况下,使用长提示词生成的图片效果会更好,同时该模型还不支持Guess Mode 猜测模型,在使用的时候需要注意。
5、lineart 写实线稿
lineart 线稿模型也是根据线稿生成特定风格的图像,同样对应 3 个预处理器,分别是 coarse / realistic/ standard ,coarse 属于粗略模式,细节部分丢失得比较多;realistic 属于精细模式,细节部分就画得比较完整;standard 标准模式,该模式有点类似于涂鸦的 xdog 模型,但它是以线条的形式体现出来,具体效果可以看下图,大家也可以自己尝试尝试。

6、mlsd 直线检测
mlsd 直线检测类似于线稿和边缘检测,但其更适合处理带有大量直线的图片,比如建筑和室内空间等。

7、normalbae 法线贴图
normalbae 法线贴图模型,主要用于模拟3D模型表面的细节以及纹理,可以保留较为精确的角色细节,对场景及人物的还原都比较好,其对应的预处理器为 normal_bae。

8、openpose 姿态检测
openpose 也是用得比较多的一种模型,可以根据原图生成对应的人体姿态图像,再通过这个姿态图去控制生成的人物姿态手势等。新版本中,该模型对应的预处理器被分成了好多种,除了 openpose 与原版本相同之外,另外增加了脸部跟手部的细节检测,分别是face / faceonly / full / hand ,具体如下图,可以看出功能比原版本强大了很多,特别是手的部分处理得更加精确。

9、scribble 涂鸦
scribble 涂鸦模型,可以理解为更粗糙的线稿模型,对应的有三种预处理器。分别是 hed / pidinet / xdog ,前面两种是 1.0 版本原有的涂鸦方式,新版本主要多了 xdog 的预处理器, xdog 是基于高斯差分的图像边缘检测算法,这种算法可以让我们得到一张具有良好边缘的边缘图像,从以下对比图就可以看出有明显的差别。

除以上几种预处理器外,模型还可以接受手绘的涂鸦。
10、seg 语义分割
首先介绍一下语义分割,语义分割就是把整个画面用颜色分割成不同的区域,每个颜色都有自己独特的代表意义,具体代表什么可以参考下面这张图。这样想要在图中什么位置出现什么物体,就在那个位置用对应的颜色标示出来,然后放到AI绘画里面就能自动识别。

seg 语义分割模型同样也是有 3 个对应的预处理器,分别是 ofade20k / ufade20k / ofcoco ,预处理器可以将原图按对应的语义使用颜色进行填充,然后模型再根据这些语义颜色来生成对应的物体,从而改变风格。
从名称可以看出来 ofade20k 与 ufade20k 都是基于 ade20k 协议的,它支持150多种颜色,而 ofcoco 是基于 coco协议的,它额外还支持 182 种颜色,颜色数量上就翻了一倍,从这也可以看出这个预处理器相比另外两个效果上会更好。
11、shuffle 图像重组
该模型目前还处于测试当中,其功能是使用随机流来打乱原图像再控制 Stable diffusion 来重组图像,然后再根据提示词或者其他 ControlNet 来改变图像的风格。
试了几组图像,但我还是看不出该模型的特点在哪里。

12、softedge 软边缘
softedge软边缘模型,功能与其他边缘模型差不多,对应有4种预处理器,分别是hed / hedsafe / pidinet / pidisafe , 可以理解为 1.0 版本 hed 算法的升级版,但升级后的版本效果明显比原版本更好。

新版本的算法更倾向于将损坏的原始图像灰度隐藏在软边缘图中,而旧版本则是通过过度拟合的方式来隐藏损坏的图像,而不是软边缘的形式。
hed 与 pidinet 都是边缘检测算法,后面加了个 safe 是在原有的基础上增加了一些安全措施,防止生成的图像带有一些不好的内容。
这几个算法中,官方比较推荐的是 pidinet ,因为大多数情况下,这个算法会更稳定。
13、ip2p 指令
这个模型也是一个处于测试当中的模型,没有与之对应的预处理器,它是通过一半的描述提示词和一半的指令提示词来完成图片的变化效果的,例如:“一个可爱的女孩”是描述提示词,“让女孩变得可爱”则是指令提示词。
可以通过指令的形式来改变图片的风格,比如下图的指令是:make it on fire.(让它着火)

14、tile (未完成)
该模型目前还处于未完成的状态,暂时不做介绍 ,等后面模型稳定了再行补充。
以上就是新版 ControlNet 扩展插件的基本内容,使用的方式有很多种,也比较复杂,后面再慢慢结合其他模型或者实例来详细介绍。
















暂无评论内容