
作者 | Ezequiel Lanza、Ruonan Wang
译者 | 刘志勇
策划 | Tina
本文最初发表于 Medium 博客,经原作者授权,InfoQ 翻译并分享。
导读:本文介绍了如何使用 Stable Diffusion 模型从文本生成图像。作者详细介绍了该模型的架构概述以及学习过程,并指出该模型需要大量计算,但可以使用英特尔提供的优化技术缩短运行时间。同时,文章还提供了文本到图像的实现步骤,并鼓励读者在 GitHub 上跟随实现。
如果说每种技术都有其季节,那么人工智能已经迎来了“夏天”。人工智能的一系列进步引领了该学科目前的繁荣,并带来了对未来的巨大期望。
计算机视觉就是一个典型例子。尽管对计算资源的需求很高,但在图像生成(Huang 等,2018)领域已经取得了巨大的进展。图像生成始于生成式对抗网络(Generative Adversarial Network,GAN)范式,然后逐步发展到如今的扩散模型。这种进化为数据科学家提供了易于训练、快速收敛并能可靠生成高质量图像的模型。
这种技术在人工智能内容生成(generative AI,AIGC)中发挥着重要作用,它能够生成各种数据,包括音频、代码、图像、文本、模拟、3D 对象、视频等等。它通过训练算法来基于以前的训练数据生成新的信息。AIGC 有许多用途包括文本生成(如 GPT,Bidirectional Encoder Representations from Transformer(BERT)或最近的 ChatGPT)、音频生成、文本到图像的创建(DALL-E 或 Stable Diffusion)等。
在本文中,我们将展示如何借助 BigDL( BigDL Nano 中的优化)在 Intel 笔记本电脑上运行优化后的 Stable Diffusion 模型,从而实现文本到图像的生成。
使用 Stable Diffusion 的两种方法
使用 Stable Diffusion 生成图像有两种方式:无条件和有条件。
无条件图像生成:可以从噪声种生成新的图像而不需要任何条件(例如提示文本或其他图像)。模型在训练之后可以生成新的随机图片。相关详细信息,请查看此使用蝴蝶图像训练模型的示例。

训练集

生成的图像
有条件图像生成:该模型可以根据输入条件生成新的图像,而有条件图像生成的具体应用包括文本到图像、图像到图像、语义、修补和补全等。让我们来详细看一下:
文本到图像(txt2img):基于输入文本生成图像。输入:文本-> 输出:图像以下是一个输入文本的示例:一只戴眼镜的狗。


摘自《基于潜在扩散模型的高分辨率图像合成》(High-Resolution Image Synthesis with Latent Diffusion Models)


海滩(上图)带高尔夫球场的海滩(下图)

家庭办公室(来自 UnSplash 的原始照片)

带有生成的斗篷十字军面具的家庭办公室


Stable Diffusion 的工作原理:概述
Stable Diffusion 是用于高分辨率图像生成的模型。为了理解扩散模型的工作原理,而不深入复杂的数学原理,我们将一个 txt2img 稳定扩散模型分解为三个主要部分:
文本编码器:是一个基于 Transformer 的 ClipText 模型,采取和 GPT 一样的架构。Transformer 已经证明了对语言的良好理解,因此它们可以基于你文本提示的意图轻松地识别和转换。图像信息生成器(基于文本信息的 UNET):这是扩散发生的地方。在这一部分中使用了 U-Net(Resnet-CNN 架构)网络,在推理之前该网络已经进行了训练。扩散理论可以分解为前向扩散和反向扩散两个主要过程。工作原理是首先通过逐渐添加高斯噪声来破坏训练数据,然后通过学习反转噪声来恢复数据。预处理阶段:正向扩散过程,通过不断添加高斯噪声来破坏训练数据,以生成训练样本,对应下图从右到左的过程。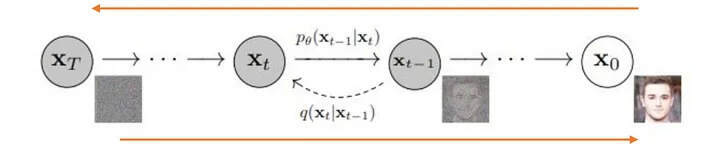
图片来源(Ho 等人,2020 年)
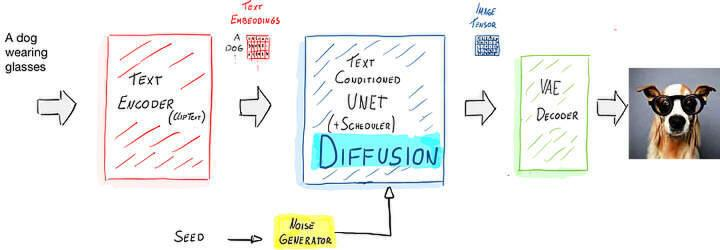
架构概述。图片来源:Ezequiel Lanza
BigDL
你可以使用上述的架构来获得图像,但是你是否注意到这个过程需要很长时间,有时需要几分钟?
这是因为我们使用的模型很大,但可以通过优化来减少处理时间。具体哪些部分可以进行优化,这里不再详细介绍。优化已经被集成到了 BigDL 中,其考虑了多种优化,例如 Intel® Optimization for TensorFlow,Intel® Extension for PyTorch,Intel® Distribution of OpenVINO,Intel® AVX-512 等等。

BigDL 架构。图:Ruonan Wang
使用 BigDL 生成图像
现在轮到你了。我们将在这里为你提供步骤,或者你可以在 GitHub 上跟随实现。

安装
我们建议使用至少 16GB RAM 和 15GB 可用磁盘空间的 Intel 笔记本电脑/台式机。
为了访问我们提供的实现,建议使用新的虚拟环境运行,并安装必要的先决条件。
conda create -n sd python=3.8 conda activate sd pip install -r requirements.txt启动 Web UI
打开你下载文件的文件夹,然后运行启动脚本:
python launch.py随后应用程序将在你的设备上运行,并且你可以在浏览器中输入此地址:http://127.0.0.1:7860/
优化模型
在生成图像之前,你需要获取优化后的模型。 请转到“优化模型”选项卡执行操作。

现在你可以选择以下两个选项:
CPU-FP32 将为 CPU 生成优化后的 fp32 模型,后面会出现“CPU FP32”选项(例如“v2.1-base CPU FP32”)。CPU / iGPU FP16 将为 CPU 和 iGPU 生成优化后的 fp16 模型,后面将出现两个“FP16”选项(例如“v2.1-base CPU FP16”,“v2.1-base CPU+iGPU FP16”)。注意:这一步可能需要一些时间,因为应用程序会实时下载原始模型并为你进行优化。
模型优化完成后,你可以键入任何文本以生成原始图像。

注意:由于我们正在使用 Hugging Face 模型,你需要按照上图所示添加访问令牌。
现在你的模型已准备就绪,你可以从“txt2img”选项卡开始生成图像。此外,应用程序还提供了其他选项。

总结
Stable Diffusion 是一种功能强大的工具,具有革命性的潜力,可应用于许多现实世界的场景。本文介绍的模型及其学习过程需要大量计算,Intel 提供的优化技术可以缩短处理时间。如果想获取更多来自 Intel 的开源内容,请访问 open.intel 或关注我们的 Twitter。
作者简介:
Ezequiel Lanza 是英特尔开放生态系统团队的开源倡导者,热衷于帮助人们发现令人兴奋的人工智能世界。他还是经常参加人工智能会议的演讲者,创建使用案例、教程和指南,帮助开发人员采用像 TensorFlow 和 Hugging Face 这 样的开源人工智能工具。
Ruonan Wang 是英特尔 AIA 的人工智能框架工程师,目前专注于开发 BigDL-Nano,这是一个 Python 包,可以在英特尔硬件上透明加速 PyTorch 和 TensorFlow 应用程序。
原文链接:
https://medium.com/intel-tech/bigdl-tutorial-generate-your-own-images-from-text-with-stable-diffusion-63f45634ab2c
本文转载来源:
https://www.infoq.cn/article/sbYgeIQPwWH6q7DXvLsj



















暂无评论内容