
注:感兴趣的可以直接查看原文,为了避免自己的理解出现偏差,这里把原文和我的翻译对照着提供。如果觉得翻译有问题可以评论指正。
原文地址: https://jalammar.github.io/illustrated-stable-diffusion/
AI image generation is the most recent AI capability blowing peoples minds (mine included). The ability to create striking visuals from text descriptions has a magical quality to it and points clearly to a shift in how humans create art. The release ofStable Diffusionis a clear milestone in this development because it made a high-performance model available to the masses (performance in terms of image quality, as well as speed and relatively low resource/memory requirements).
人工智能图像生成是最新最热门的人工智能能力。从文字描述中创造出引人注目的视觉效果的能力具有一种神奇的特质,并且清楚地指出了人类创造艺术的方式的转变。Stable Diffusion的发布是这个开发中的一个明显的里程碑,因为它向大众提供了一个高性能的模型(在图像质量、速度和相对较低的资源/内存需求方面的性能)。
After experimenting with AI image generation, you may start to wonder how it works.
在试验了人工智能图像生成之后,你可能会想知道它是如何工作的。
This is a gentle introduction to how Stable Diffusion works.
这是对Stable Diffusion如何工作的一个温和的介绍。

Stable Diffusion is versatile in that it can be used in a number of different ways. Lets focus at first on image generation from text only (text2img). The image above shows an example text input and the resulting generated image (The actual complete prompt is here). Aside from text to image, another main way of using it is by making it alter images (so inputs are text + image).
Stable Diffusion是多才多艺的,因为它可以在许多不同的方式使用。让我们首先关注仅从文本生成图像(text2img)。上面的图像显示了一个文本输入示例和生成的图像(实际的完整提示在这里)。除了文本到图像之外,使用它的另一个主要方法是使它改变图像(所以输入是文本 + 图像)。

Lets start to look under the hood because that helps explain the components, how they interact, and what the image generation options/parameters mean.
让我们开始深入研究,因为这有助于解释组件、它们如何交互以及图像生成选项/参数的含义。
1、Stable Diffusion的模型组件
The Components of Stable Diffusio
Stable Diffusion is a system made up of several components and models. It is not one monolithic model.
Stable Diffusion是一个由多个部件和模型组成的系统,它不是一个整体模型。
As we look under the hood, the first observation we can make is that theres a text-understanding component that translates the text information into a numeric representation that captures the ideas in the text.
当我们深入研究的时候,我们首先发现有一个文本理解组件,它将文本信息转换为数字表示,从而捕捉文本中的想法。

Were starting with a high-level view and well get into more machine learning details later in this article. However, we can say that this text encoder is a special Transformer language model (technically: the text encoder of a CLIP model). It takes the input text and outputs a list of numbers (a vector) representing each word/token in the text.
我们从一个高层次的视图开始,在本文后面我们将进入更多的机器学习细节。但是,我们可以说这个文本编码器是一个特殊的 Transformer 语言模型(从技术上讲: CLIP 模型的文本编码器)。它获取输入文本并输出一个数字列表(一个向量) ,该列表表示文本中的每个单词/标记。
That information is then presented to the Image Generator, which is composed of a couple of components itself.
然后,这些信息被呈现给图像生成器,该生成器由两个组件本身组成。

The image generator goes through two stages:
图像生成器经历了两个阶段:
1- Image information creator
图像信息创建器
This component is the secret sauce of Stable Diffusion. Its where a lot of the performance gain over previous models is achieved.
这个成分是Stable Diffusion的秘密武器。这就是比以前的模型获得更多性能提升的地方。
This component runs for multiple steps to generate image information. This is the steps parameter in Stable Diffusion interfaces and libraries which often defaults to 50 or 100.
此组件运行多个步骤来生成图像信息。这是Stable Diffusion接口和库中的步骤参数,它们通常默认为50或100。
The image information creator works completely in the image information space (or latent space). Well talk more about what that means later in the post. This property makes it faster than previous diffusion models that worked in pixel space. In technical terms, this component is made up of a UNet neural network and a scheduling algorithm.
图像信息生成器完全在图像信息空间(或潜在空间)中工作。稍后我们会详细讨论这意味着什么。这个特性使它比以前在像素空间中工作的扩散模型更快。从技术上讲,这个组件由 UNet 神经网络和调度算法组成。
The word “diffusion” describes what happens in this component. It is the step by step processing of information that leads to a high-quality image being generated in the end (by the next component, the image decoder).
“扩散”这个词描述了在这个组件中发生的事情。正是对信息的逐步处理最终产生了高质量的图像(由下一个组件,图像解码器)。
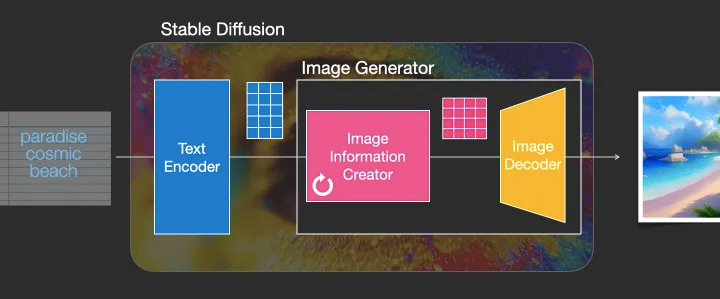
2- Image Decoder
图像解码器
The image decoder paints a picture from the information it got from the information creator. It runs only once at the end of the process to produce the final pixel image.
图像解码器根据从信息创建者处获得的信息绘制图像。它只在过程结束时运行一次,以生成最终的像素图像。

With this we come to see the three main components (each with its own neural network) that make up Stable Diffusion:
这样,我们就可以看到构成Stable Diffusion的三个主要组成部分(每个部分都有自己的神经网络) :
ClipText for text encoding.
Input: text.
Output: 77 token embeddings vectors, each in 768 dimensions.
用于文本编码的ClipText。输入: 文本。输出: 77个标记嵌入向量,每个向量有768个维度。UNet + Scheduler to gradually process/diffuse information in the information (latent) space.
Input: text embeddings and a starting multi-dimensional array (structured lists of numbers, also called a tensor) made up of noise.
Output: A processed information array
UNet + 调度程序: 在信息(潜在)空间中逐步处理/传播信息。输入: 文本嵌入和一个初始化的多维数组(结构化的数字列表,也称为张量)组成的噪声。输出: 经过处理的信息数组Autoencoder Decoder that paints the final image using the processed information array.
Input: The processed information array (dimensions: (4,64,64))
Output: The resulting image (dimensions: (3, 512, 512) which are (red/green/blue, width, height))
Autoencoder Decoder: 使用处理过的信息数组绘制最终图像。输入: 处理过的信息数组(尺寸: (4,64,64))输出: 生成的图像(尺寸: (3,512,512) ,它们是(红/绿/蓝,宽度,高度)
2、什么是Diffusion
What is Diffusion Anyway?
Diffusion is the process that takes place inside the pink “image information creator” component. Having the token embeddings that represent the input text, and a random starting image information array (these are also called latents), the process produces an information array that the image decoder uses to paint the final image.
扩散是发生在粉红色“图像信息创建者”组件内部的过程。具有表示输入文本的token embeddings和随机起始图像信息数组(也称为latents) ,该过程生成图像解码器用于绘制最终图像的信息数组。

This process happens in a step-by-step fashion. Each step adds more relevant information. To get an intuition of the process, we can inspect the random latents array, and see that it translates to visual noise. Visual inspection in this case is passing it through the image decoder.
这个过程以一步一步的方式进行。每一步都增加了更多的相关信息。为了得到一个直观的过程,我们可以检查随机latents数组,并看到它转化为视觉噪声。在这种情况下是通过它的图像解码器进行视觉检查的。
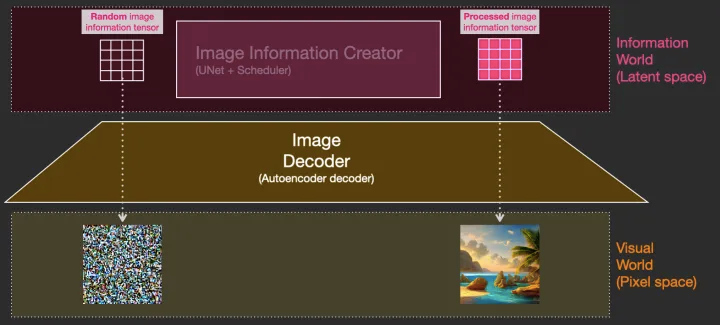
Diffusion happens in multiple steps, each step operates on an input latents array, and produces another latents array that better resembles the input text and all the visual information the model picked up from all images the model was trained on.
扩散发生在多个步骤中,每个步骤操作一个输入latents数组,并产生另一个更好的结合了输入文本和所有视觉信息的latents数组模型(模型从训练中的所有图像中pick up出来的)。

We can visualize a set of these latents to see what information gets added at each step.
我们可以可视化一组这样的潜在信息,看看在每个步骤中添加了什么信息。
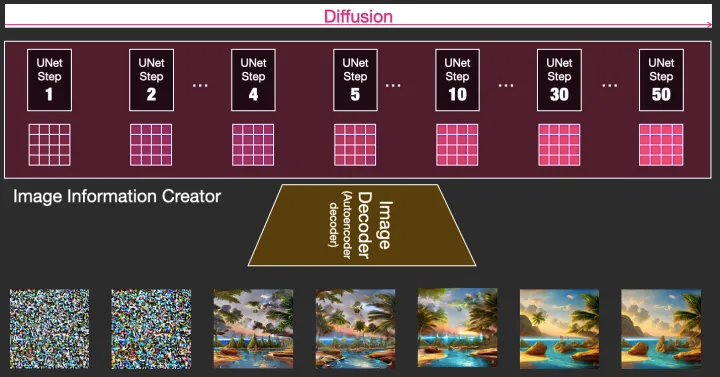
The process is quite breathtaking to look at
这个过程看起来非常惊人

Something especially fascinating happens between steps 2 and 4 in this case. Its as if the outline emerges from the noise.
在这种情况下,步骤2和步骤4之间发生了一些特别有趣的事情。就好像轮廓是从噪音中浮现出来的。
diffusion如何工作
How diffusion works
The central idea of generating images with diffusion model relies on the fact that we have powerful computer vision models. Given a large enough dataset, these models can learn complex operations. Diffusion models approach image generation by framing the problem as following:
利用扩散模型生成图像的核心思想依赖于我们拥有强大的计算机视觉模型这一事实。给定一个足够大的数据集,这些模型可以学习复杂的操作。扩散模型通过将问题框定如下来处理图像生成:
Say we have an image, lets take a first step of adding some noise to it.
首先假设我们有一个图像,让我们首先给它添加一些噪音(这就是扩散模型中的加噪过程)。

Lets call the “slice” of noise we added to the image “noise slice 1”. Lets now take another step adding some more noise to the noisy image (“noise slice 2”).
让我们把我们添加到图像中的“噪声片”称为“噪声片1”。现在让我们进行另一个步骤,在噪声图像中添加更多的噪声(“噪声片2”)。

At this point, the image is made entirely of noise. Now lets take these as training examples for a computer vision neural network. Given a step number and image, we want it to predict how much noise was added in the previous step.
此时,(我们假设)图像(已经)完全由噪音构成。现在让我们把这些作为计算机视觉神经网络的训练例子。给定一个步数和图像,我们希望它能够预测在前一步中添加了多少噪声(这就是扩散模型加噪的训练数据怎么生成的,一般是加入的噪声是高斯噪声)。
While this example shows two steps from image to total noise, we can control how much noise to add to the image, and so we can spread it over tens of steps, creating tens of training examples per image for all the images in a training dataset.
虽然这个例子展示了从图像到总噪声的两个步骤,但是我们可以控制向图像添加多少噪声,因此我们可以将它分散到几十个步骤中,为一个训练数据集中的所有图像创建每个图像的几十个训练例子。(每个图像加50步的噪声,那么我们就得到了50个训练样本)
The beautiful thing now is that once we get this noise prediction network working properly, it can effectively paint pictures by removing noise over a number of steps.
现在美妙的事情是,一旦我们得到这个噪音预测网络正常工作,它可以通过消除噪音的一些步骤有效地绘制图片(这就是扩散模型的降噪过程,用来生成高质量的图像)。
Note: This is a slight oversimplification of the diffusion algorithm. The resources at the bottom give you the whole mathematical picture in more detail.
注意: 这是扩散算法的一个轻微的过度简化。底部的资源给你整个数学图片的更多细节。
通过降噪来绘图
Painting images by removing noise
The trained noise predictor can take a noisy image, and the number of the denoising step, and is able to predict a slice of noise.
经过训练的噪声预测器可以对一幅噪声图像进行去噪,并对去噪步数进行预测,并能对一片噪声进行预测。
The slice of noise is predicted so that if we subtract it from the image, we get an image thats closer to the images the model was trained on.
噪声片被预测,所以如果我们从图像中减去它,我们得到的图像更接近模型训练的图像。
If the training dataset was of aesthetically pleasing images (e.g., LAION Aesthetics, which Stable Diffusion was trained on), then the resulting image would tend to be aesthetically pleasing.
如果训练数据集是美学上令人愉快的图像(例如,LAION 美学数据集,Stable Diffusion的训练集) ,那么结果图像将趋向于美学上令人愉快。
This concludes the description of image generation by diffusion models mostly as described inDenoising Diffusion Probabilistic Models. Now that you have this intuition of diffusion, you know how the main components of not only Stable Diffusion, but also Dall-E 2 and Googles Imagen.
本文总结了扩散模型对图像生成的描述,主要是在去噪扩散概率模型中描述的。既然你已经有了这种扩散的直觉,你就知道了扩散不仅是Stable Diffusion的主要组成部分,还是 Dall-E 2和 Google 的 Imagen的主要部分。
Note that the diffusion process we described so far generates images without using any text data. In the next sections well describe how text is incorporated in the process.
注意,我们到目前为止描述的扩散过程不使用任何文本数据生成图像。在接下来的部分中,我们将描述如何将文本合并到流程中。
3、加速:在潜在空间而不是图像像素空间进行扩散
Speed Boost: Diffusion on Compressed (latent) Data Instead of the Pixel Image
To speed up the image generation process, the Stable Diffusion paper runs the diffusion process not on the pixel images themselves, but on a compressed version of the image.The paper calls this “Departure to Latent Space”.
为了加快图像生成过程,Stable Diffusion 、运行的扩散过程不是在像素图像本身,而是在图像的压缩版本。这篇论文称之为“离开潜在空间”。
This compression (and later decompression/painting) is done via an autoencoder. The autoencoder compresses the image into the latent space using its encoder, then reconstructs it using only the compressed information using the decoder.
这种压缩(以及后来的解压缩/绘制)是通过自动编码器完成的。自动编码器使用编码器将图像压缩到潜在空间,然后使用解码器仅使用压缩信息重建图像。
Now the forward diffusion process is done on the compressed latents. The slices of noise are of noise applied to those latents, not to the pixel image. And so the noise predictor is actually trained to predict noise in the compressed representation (the latent space).
现在正向扩散过程是在压缩潜在空间上进行的。噪声切片是应用于这些潜在空间的噪声,而不是像素图像。因此噪声预测器实际上被训练来预测压缩表示(潜在空间)中的噪声。
The forward process (using the autoencoders encoder) is how we generate the data to train the noise predictor. Once its trained, we can generate images by running the reverse process (using the autoencoders decoder).
正向处理(使用自动编码器的编码器)是我们如何生成数据来训练噪声预测器。一旦它被训练,我们可以通过运行相反的过程(使用自动编码器的解码器)来生成图像。
These two flows are whats show in Figure 3 of the LDM/Stable Diffusion paper:
这两个流程如Stable Diffusion论文的图3所示:
This figure additionally shows the “conditioning” components, which in this case is the text prompts describing what image the model should generate. So lets dig into the text components.
此图还显示了“conditioning”组件,在本例中是描述模型应该生成的图像的文本提示。让我们深入研究一下文本组件。
Text Encoder: 基于Transformer的语言模型
The Text Encoder: A Transformer Language Model
A Transformer language model is used as the language understanding component that takes the text prompt and produces token embeddings. The released Stable Diffusion model uses ClipText (AGPT-based model), while the paper usedBERT.
我们使用了一个 Transformer 语言模型作为语言理解组件,该组件接受文本prompt并产生token embeddings。发布的Stable Diffusion模型使用 ClipText (基于 GPT 的模型) ,而本文使用 BERT。
The choice of language model is shown by the Imagen paper to be an important one. Swapping in larger language models had more of an effect on generated image quality than larger image generation components.
Imagen 的论文表明,语言模型的选择是一个重要问题。使用较大的语言模型中对生成的图像质量的影响大于使用较大的图像生成组件。
Larger/better language models have a significant effect on the quality of image generation models. Source: <a href=Google Imagen paper by Saharia et. al.. Figure A.5.更大/更好的语言模型对图像生成模型的质量有重要影响。” data-size=”normal” data-watermark=”original” data-original-src=”https://pic4.zhimg.com/80/v2-2a83f3536f9b1e8445907a125a2a7b2b_r.png“/>
The early Stable Diffusion models just plugged in the pre-trained ClipText model released by OpenAI. Its possible that future models may switch to the newly released and much largerOpenCLIPvariants of CLIP. This new batch includes text models of sizes up to 354M parameters, as opposed to the 63M parameters in ClipText.
早期的Stable Diffusion模型刚刚插入了 OpenAI 发布的经过预训练 ClipText 模型。未来的模型可能会转向新发布的更大的 OpenCLIP 。与 ClipText 中的63M 参数相反,这个新模型包括最大大小为354M 参数的文本模型。
CLIP是怎么训练的
How CLIP is trained
CLIP is trained on a dataset of images and their captions. Think of a dataset looking like this, only with 400 million images and their captions:
CLIP 在图像及其标题的数据集上进行训练。想象一下这样的数据集,只有4亿张图片和对应的说明:
A dataset of images and their captions.CLIP is a combination of an image encoder and a text encoder. Its training process can be simplified to thinking of taking an image and its caption. We encode them both with the image and text encoders respectively.
CLIP 是图像编码器和文本编码器的组合。它的训练过程可以简化为图像和文字说明的匹配过程。我们分别用图像编码器和文本编码器对它们进行编码。
We then compare the resulting embeddings using cosine similarity. When we begin the training process, the similarity will be low, even if the text describes the image correctly.
然后我们使用余弦距离比较编码器编码后的embeddings。当我们开始训练过程中,相似性会比较低,即使文本描述和图像是匹配的。
We update the two models so that the next time we embed them, the resulting embeddings are similar.
我们更新这两个模型,以便再遇到图文对时,文本描述和图像的embedding是相似的。
By repeating this across the dataset and with large batch sizes, we end up with the encoders being able to produce embeddings where an image of a dog and the sentence “a picture of a dog” are similar. Just like inword2vec, the training process also needs to include negative examples of images and captions that dont match, and the model needs to assign them low similarity scores.
通过在整个数据集中重复这个过程,并使用大batch size,我们最终能够产生两个编码器,这两个编码器分别对一个狗的图像和句子“一个狗的图片”编码,编码生成的embedding是相似的。就像在 word2vec 中一样,训练过程也需要包括不匹配的图片和prompt的负面例子,模型需要给它们分配较低的相似度分数。
4、在图像生成过程加入文本信息
Feeding Text Information Into The Image Generation Process
To make text a part of the image generation process, we have to adjust our noise predictor to use the text as an input.
为了使文本成为图像生成过程的一部分,我们必须调整噪声预测器,使用文本作为输入。
Our dataset now includes the encoded text. Since were operating in the latent space, both the input images and predicted noise are in the latent space.
们的数据集现在包括被编码的文本。由于我们在潜在空间中操作,输入图像和预测噪声都在潜在空间中。
To get a better sense of how the text tokens are used in the Unet, lets look deeper inside the Unet.
为了更好地了解文本在 Unet 中的使用方式,让我们深入了解一下 Unet。
Unet Noise predictor (without text)
Lets first look at a diffusion Unet that does not use text. Its inputs and outputs would look like this:
让我们首先来看一个不使用文本的扩散 Unet,它的输入和输出如下所示:
Inside, we see that:
The Unet is a series of layers that work on transforming the latents array. Unet是一系列转换潜在数组的神经网络层Each layer operates on the output of the previous layer. 每一层操作前一层的输出Some of the outputs are fed (via residual connections) into the processing later in the network. 一些输出(通过残差连接)被送入网络后面的处理中The timestep is transformed into a time step embedding vector, and thats what gets used in the layers. 时间步长被转换成一个时间步长嵌入向量,这就是在层中使用的内容Unet Noise predictor with text
Lets now look how to alter this system to include attention to the text.
现在让我们看看如何改变这个系统,以包括对文本的attention。
The main change to the system we need to add support for text inputs (technical term: text conditioning) is to add an attention layer between the ResNet blocks.
我们需要添加对文本输入的支持(技术术语: text conditioning)的系统的主要更改是在 ResNet 块之间添加一个注意层。
Note that the resnet block dont directly look at the text. But the attention layers merge those text representations in the latents. And now the next ResNet can utilize that incorporated text information in its processing.
请注意,resnet 块不直接查看文本。但是注意层将这些文本表征合并到潜在空间中。现在,下一个 ResNet 可以在处理过程中利用合并的文本信息
Conclusion
I hope this gives you a good first intuition about how Stable Diffusion works. Lots of other concepts are involved, but I believe theyre easier to understand once youre familiar with the building blocks above. The resources below are great next steps that I found useful. Please reach out to me onTwitter for any corrections or feedback.
我希望这能给你一个关于Stable Diffusion如何工作的良好的第一直觉。其中涉及到许多其他的概念,但是我相信一旦你熟悉了上面的构建模块,就会更容易理解它们。下面的资源是我发现非常有用的下一步。请在 Twitter 上联系我,以获得更正或反馈。
Resources
I have a one-minute YouTube shorton usingDream Studio to generate images with Stable Diffusion.Stable Diffusion with DiffusersThe Annotated Diffusion ModelHow does Stable Diffusion work? – Latent Diffusion Models EXPLAINED [Video]Stable Diffusion – What, Why, How? [Video]High-Resolution Image Synthesis with Latent Diffusion Models[The Stable Diffusion paper]For a more in-depth look at the algorithms and math, see Lilian WengsWhat are Diffusion Models?Citation
If you found this work helpful for your research, please cite it as following:
















暂无评论内容