
作者: 单华 Refinitiv创新实验室ARGO
自然语言处理(Natural Language Processing,NLP)是一门集语言学,数学及计算机科学于一体的科学。它的核心目标就是把人的自然语言转换为计算机可以阅读的指令,简单来说就是让机器读懂人的语言。
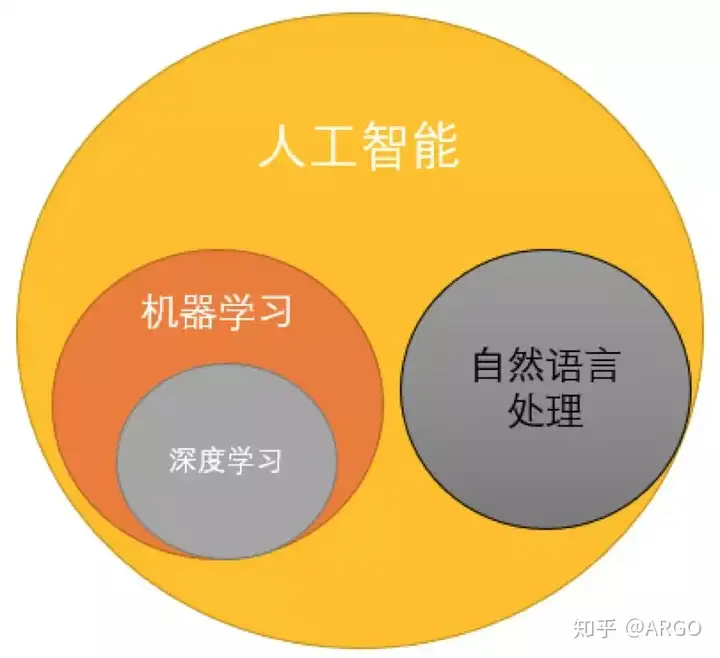
NLP是人工智能领域一个非常重要的分支,其它重要分支包括计算机视觉,语音及机器学习和深度学习等。那么,NLP与机器学习,深度学习有什么关系呢?我们可以用下面的图来表示。可以看出,深度学习是机器学习的其中一个分支,而自然语言处理与机器学习之间是并行的,机器学习为自然语言处理提供了解决问题的许多模型和方法。所以,二者之间具有密不可分的关系。
本文将从以下几方面为您简要介绍NLP:
NLP的常用研究方法NLP的基本知识NLP的常见应用NLP的发展难点一 NLP的常用研究方法
研究自然语言处理,通常有三种方法:
第一种,机器学习的方法,也包括深度学习。简单来说我们收集海量的文本、数据,建立语言模型,解决自然语言处理的任务。
第二种,规则和逻辑的方法。我们都知道,人的语言的组成具有很强的逻辑性,一些传统的逻辑、原理都可以用在上面,其实这也是人工智能最早主要的研究方法,只不过90年代之后大家逐渐开始更多的采用机器学习的方法。现在基本上在自然语言处理研究当中,逻辑和规则占20%,机器学习占80%,也有两者结合。
第三种,语言学的方法。因为自然语言处理离不开语言学,我们可以把自然语言处理看成语言学下面的一个分支,不单单看成人工智能下面的一个分支。语言学用一句话归纳起来就是对人的语言现象的研究。它不关心怎么写得好,关心的是你写了什么。所有对人类语言现象的研究都可以归为语言学,从这方面来说,语言学家也就是很多自然语言处理任务的设计师,由他们提出问题,把框架勾勒出来;当然解决问题则要靠研究人员用机器学习、规则和逻辑的方法把这个框架填上,把问题解决掉。
二 NLP的基本知识
分词
词是承载语义的最基本单位,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记。分词作为信息检索,情感分析,文本分类等自然语言处理任务的重要基础,具有重要意义。
中文分词技术可分为三大类:基于字典、词库匹配的分词方法;基于词频统计的分词方法和基于知识理解的分词方法。
http://www.cnblogs.com/flish/archive/2011/08/08/2131031.html
词性标注
词性标注(Part-of-Speech tagging/POS tagging),又称词类标注或者简称标注,是给句子中每个词赋予一个词性类别的过程,这里的词性类别可以是名词、动词、形容词或其他词性。在汉语中,词性标注比较简单,因为汉语词汇词性多变的情况比较少见,大多词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。据说,只需选取最高频词性,即可实现达到80%准确率的中文词性标注程序。利用隐马尔科夫模型(Hidden Markov Model,HMM)即可实现更高准确率的词性标注 。
词性作为对词的一种泛化,在语言识别、句法分析、信息抽取等任务中有重要作用。
http://blog.csdn.net/truong/article/details/18847549
命名实体识别
命名实体识别(Named Entity Recognition,NER),是指在句子的词序列中识别并定位文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。 它主要包含两部分:
(1)实体边界识别;
(2)确定实体类别(人名、地名、机构名或其他)
命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向SemanticWeb的元数据标注等应用领域的重要基础工具。
https://blog.csdn.net/u012879957/article/details/81777838
依存句法分析
依存语法(Dependency Parsing, DP)通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
语义角色标注
语义角色标注 (Semantic Role Labeling, SRL)是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元(语义角色),如施事、受事、时间和地点等。其能够对问答系统、信息抽取和机器翻译等应用产生推动作用。
https://www.cnblogs.com/CheeseZH/p/5768389.html
指代消解
指代是一种常见的语言现象,一般情况下,指代分为2种:回指和共指。
回指是指当前的照应语与上文出现的词、短语或句子(句群)存在密切的语义关联性,指代依存于上下文语义中,在不同的语言环境中可能指代不同的实体,具有非对称性和非传递性;
共指主要是指2个名词(包括代名词、名词短语)指向真实世界中的同一参照体,这种指代脱离上下文仍然成立。
目前指代消解研究主要侧重于等价关系,只考虑2个词或短语是否指示现实世界中同一实体的问题,即共指消解。
中文的指代主要有3种典型的形式:
(1)人称代词(pronoun),例如:李明怕高妈妈一人呆在家里寂寞,他便将家里的电视搬了过来。
(2)指示代词(demonstrative),例如:很多人都想留下什么给孩子,这可以理解,但不完全正确。
(3)有定描述(definitedescription),例如:,贸易制裁已经成为了美国政府对华的惯用大棒,这根大棒真如美国政府所希望的那样灵验吗?
https://blog.csdn.net/tcx1992/article/details/83377233
三 NLP的常见应用
文本分类
一个文本(以下基本不区分“文本”和“文档”两个词的含义)分类问题就是将一篇文档归入预先定义的几个类别中的一个或几个,而文本的自动分类则是使用计算机程序来实现这样的分类。
https://blog.csdn.net/u014248127/article/details/80774668
问答系统
问答系统(Question Answering System, QA)是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。
依据问题类型可分为:限定域和开放域两种;依据数据类型可分为:结构型和无结构型(文本);依据答案类型可分为:抽取式和产生式两种。
基于自由文本的问答系统,基本上分为三个模块:
问句分析->文档检索->答案抽取(验证)
https://blog.csdn.net/class_guy/article/details/81535287
四 NLP的发展难点
单词的边界界定:
在口语中,词与词之间通常是连贯的,在书写上,汉语也没有词与词之间的边界。而界定字词边界通常使用的办法是取用能让给定的上下文最为通顺且在文法上无误的一种最佳组合。
词义的消歧:
许多字词不单只有一个意思,因而我们必须选出使语义最为通顺的解释。
句法的模糊性:
自然语言的文法通常是模棱两可的,针对一个句子通常可能会剖析(Parse)出多棵解析树(Parse Tree),而我们必须要依赖语意及前后文的信息才能在其中选择一棵最为适合的解析树。
有瑕疵的或不规范的输入:
例如语音处理时遇到外国口音或地方口音,或者在文本的处理中处理拼写,语法或者光学字符识别(OCR)的错误。
语言行为与计划:
句子常常并不只是字面上的意思;例如,“你能把盐递过来吗”,一个好的回答应当是把盐递过去;在大多数上下文环境中,“能”将是糟糕的回答,虽说回答“不”或者“太远了我拿不到”也是可以接受的。再者,如果一门课程上一年没开设,对于提问“这门课程去年有多少学生没通过?”回答“去年没开这门课”要比回答“没人没通过”好。


















暂无评论内容