
安装 Hadoop:设置单节点 Hadoop 集群
你一定对Hadoop,HDFS及其架构有一个理论概念。 但是要获得Hadoop认证,您需要良好的实践知识。我希望你会喜欢我们之前关于HDFS架构的博客,现在我将带你了解Hadoop和HDFS的实用知识。第一步是安装Hadoop。
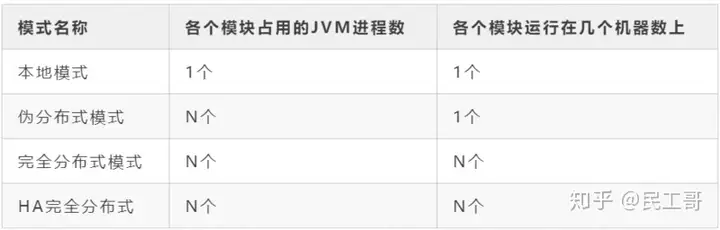
安装Hadoop有两种方法,即单节点和多节点。
单节点群集意味着只有一个数据节点在一台计算机上运行和设置所有名称节点、数据节点、资源管理器和节点管理器。这用于学习和测试目的。例如,让我们考虑医疗保健行业内部的示例数据集。因此,为了测试Oozie作业是否按适当的顺序安排了所有过程,例如收集,聚合,存储和处理数据,我们使用单节点集群。与包含分布在数百台机器上的 TB 级数据的大型环境相比,它可以在较小的环境中轻松高效地测试顺序工作流。
在多节点群集中,有多个数据节点正在运行,每个数据节点在不同的计算机上运行。多节点集群实际上在组织中用于分析大数据。考虑上面的例子,当我们实时处理PB级数据时,需要将其分布在数百台机器上进行处理。因此,这里我们使用多节点集群。
在这篇博客中,我将向您展示如何在单节点集群上安装 Hadoop。
先决条件
- 虚拟机:用于在其上安装操作系统。
- 操作系统:您可以在基于 Linux 的操作系统上安装 Hadoop。Ubuntu 和 CentOS 是非常常用的。在本教程中,我们将使用 CentOS。
- JAVA:您需要在系统上安装 Java 8 软件包。
- HADOOP:你需要Hadoop 2.7.3软件包。
安装 Hadoop
第 1 步:单击此处下载 Java 8 软件包。将此文件保存在主目录中。
第 2 步:解压缩 Java tar 文件。
命令: tar -xvf jdk-8u101-linux-i586.tar.gz

图:Hadoop 安装 – 提取 Java 文件
第 3 步: 下载 Hadoop 2.7.3 软件包。
命令:wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz

图:Hadoop 安装 – 下载 Hadoop
第 4 步: 解压缩 Hadoop tar 文件。
命令: tar -xvf hadoop-2.7.3.tar.gz

图:Hadoop 安装 – 提取 Hadoop 文件
第 5 步: 在 bash 文件 (.bashrc) 中添加 Hadoop 和 Java 路径。
打开.bashrc文件。现在,添加Hadoop和Java Path,如下所示。
通过 Hadoop 认证了解有关 Hadoop 生态系统及其工具的更多信息。
命令: vi .bashrc

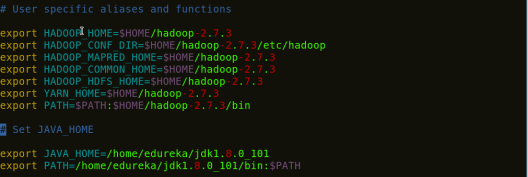
图:Hadoop 安装 – 设置环境变量
然后,保存 bash 文件并关闭它。
要将所有这些更改应用于当前终端,请执行 source 命令。
命令: sourec .bashrc

图:Hadoop 安装 – 刷新环境变量
要确保 Java 和 Hadoop 已正确安装在您的系统上,并且可以通过终端访问,请执行 java 版本和 hadoop 版本命令。
命令: java 版本
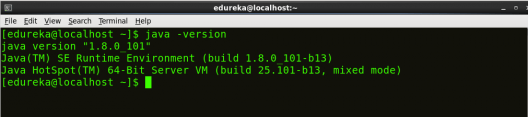
图:Hadoop 安装 – 检查 Java 版本
命令:hadoop version
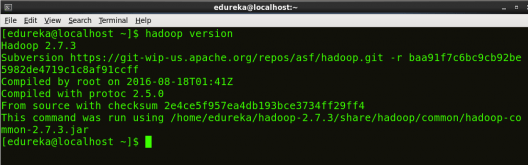
图:Hadoop 安装 – 检查 Hadoop 版本
第 6 步:编辑 Hadoop 配置文件。
命令: cd hadoop-2.7.3/etc/hadoop/
命令: ls
所有Hadoop配置文件都位于hadoop-2.7.3/etc/hadoop目录中,如下面的快照所示:
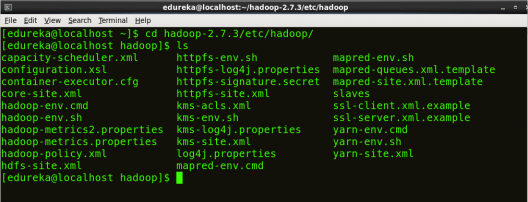
图:Hadoop 安装 – Hadoop 配置文件
第 7 步:打开核心站点.xml并在配置标记中编辑下面提到的属性:
core-site.xml 通知 Hadoop 守护进程 NameNode 在集群中的运行位置。它包含Hadoop核心的配置设置,例如HDFS和MapReduce通用的I / O设置。
命令: vi core-site.xml


图:Hadoop 安装 – 配置core-site.xml
|
1
2
3
4
5
6
7
8
|
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000</value></property></configuration> |
第 8 步:编辑 hdfs-site.xml并在配置标记中编辑下面提到的属性:
hdfs-site.xml 包含 HDFS 守护进程(即 NameNode、DataNode、Secondary NameNode)的配置设置。它还包括HDFS的复制因子和块大小。
命令: vi hdfs-site.xml


图:Hadoop 安装 – 配置 hdfs-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permission</name><value>false</value></property></configuration> |
第 9 步:编辑 mapred-site.xml 文件并在配置标记中编辑下面提到的属性:
mapred-site.xml包含MapReduce应用程序的配置设置,例如可以并行运行的JVM数量,映射器和化简器进程的大小,可用于进程的CPU内核等。
在某些情况下,mapred-site.xml 文件不可用。因此,我们必须使用 mapred-site.xml 模板创建 mapred-site.xml 文件。
命令: cp mapred-site.xml.template mapred-site.xml
命令:vi mapred-site.xml.



图:Hadoop 安装 – 配置mapred-site.xml
|
1
2
3
4
5
6
7
8
|
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration> |
第 10 步:编辑纱线站点.xml并在配置标记中编辑下面提到的属性:
yarn-site.xml包含ResourceManager和NodeManager的配置设置,如应用程序内存管理大小,程序和算法所需的操作等。
命令: vi yarn-site.xml


图:Hadoop 安装 – 配置yarn-site.xml
<?xml version="1.0"><configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>第 11 步: 编辑 hadoop-env.sh 并添加 Java 路径,如下所述:
hadoop-env.sh 包含脚本中用于运行Hadoop(如Java主路径等)的环境变量。
命令: vi hadoop–env..sh

![]()
图:Hadoop 安装 – 配置 hadoop-env.sh
第 12 步:转到 Hadoop 主目录并格式化 NameNode。
命令: cd
命令: cd hadoop-2.7.3
命令:bin/hadoop namenode -format

图:Hadoop 安装 – 格式化 NameNode
这将通过NameNode格式化HDFS。此命令仅首次执行。格式化文件系统意味着初始化由 dfs.name.dir 变量指定的目录。
切勿格式化、启动和运行 Hadoop 文件系统。您将丢失存储在HDFS中的所有数据。
第 13 步:格式化 NameNode 后,转到 hadoop-2.7.3/sbin 目录并启动所有守护进程。
命令: cd hadoop-2.7.3/sbin
您可以使用单个命令启动所有守护程序,也可以单独启动。
命令: ./start-all.sh
上面的命令是 start-dfs.sh、start-yarn.sh 和 mr-jobhistory-daemon.sh 的组合
或者,您可以单独运行所有服务,如下所示:
启动名称节点:
NameNode是HDFS文件系统的核心。它保留存储在HDFS中的所有文件的目录树,并跟踪整个集群中存储的所有文件。
命令:./hadoop-daemon.sh 启动名称节点
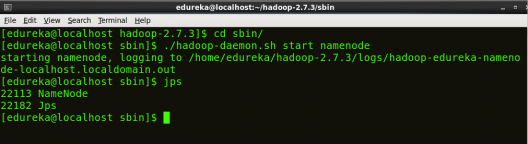
图:Hadoop 安装 – 启动名称节点
启动数据节点:
启动时,数据节点连接到名称节点,并响应来自名称节点的不同操作的请求。
命令: ./hadoop-daemon.sh 启动数据节点
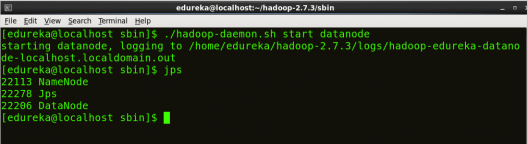
图:Hadoop 安装 – 启动 DataNode
启动资源管理器:
资源管理器是仲裁所有可用群集资源的主节点,因此有助于管理 YARN 系统上运行的分布式应用程序。它的工作是管理每个节点管理器和每个应用程序的ApplicationMaster。
命令: ./yarn-daemon.sh 启动资源管理器
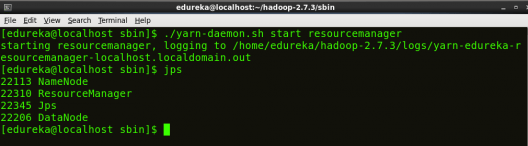
图:Hadoop 安装 – 启动资源管理器
启动节点管理器:
每个机器框架中的 NodeManager 是负责管理容器、监控其资源使用情况并向 ResourceManager 报告的代理。
命令: ./yarn-daemon.sh start nodemanager

图:Hadoop 安装 – 启动节点管理器
启动作业历史记录服务器:
JobHistoryServer 负责处理来自客户端的所有与作业历史记录相关的请求。
命令: ./mr-jobhistory-daemon.sh 启动历史记录服务器
第 14 步:要检查所有 Hadoop 服务是否已启动并正在运行,请运行以下命令。
命令: jps
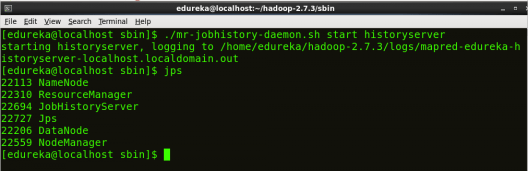
图:Hadoop 安装 – 检查守护进程
第 15 步:现在打开 Mozilla 浏览器并转到 localhost:50070/dfshealth.html 检查 NameNode 界面。
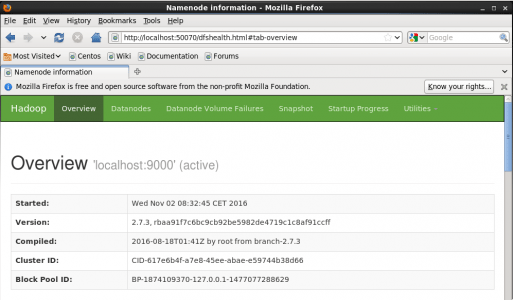
图:Hadoop 安装 – 启动 WebUI
恭喜,您已成功一次性安装单节点 Hadoop 集群。 在Hadoop教程系列的下一篇博客中,我们还将介绍如何在多节点集群上安装Hadoop。










暂无评论内容