
spark共14篇
排序

YARN资源分配,没有比这说的更清楚的了
让你彻底搞明白YARN资源分配 - 知乎 (zhihu.com)本篇要解决的问题是:Container是以什么形式运行的?是单独的JVM进程吗?YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚...
与 Hadoop 对比,如何看待 Spark 技术?
Hadoop 首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。HDFS,在由普通PC组成的集群上提供...

SPARK+HADOOP大数据实验环境配置
最近在上大数据实验的,整理一下配置环境的过程。本文主要包括所需安装包,通用配置、hadoop配置和spark配置。一.实验环境:使用虚拟机软件:VMware Workstation Pro操作系统:Ubuntu 18.04 (mas...

spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...
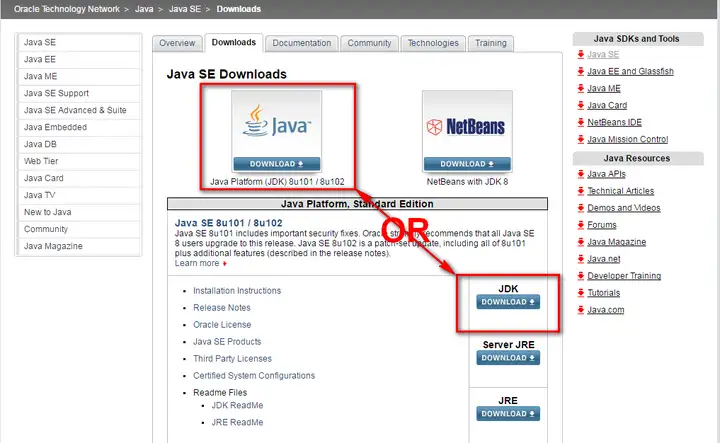
一. Spark在Windows下的环境搭建
由于Spark是用Scala来写的,所以Spark对Scala肯定是原生态支持的,因此这里以Scala为主来介绍Spark环境的搭建,主要包括四个步骤,分别是:JDK的安装,Scala的安装,Spark的安装,Hadoop的下载...

常用大数据引擎介绍,快速直达工具集
大数据平台是对海量结构化、非结构化、半机构化数据进行采集、存储、计算、统计、分析处理的一系列技术平台。大数据平台处理的数据量通常是TB级,甚至是PB或EB级的数据,这是传统数据仓库工具无...
我的面板

