
原标题:提升效率、降低成本,作业帮数据采集体系架构升级实践
作者 | 伍思磊
编辑 | 李忠良
在 ArchSummit 全球架构师峰会上海站上,InfoQ 非常荣幸邀请到作业帮大数据中台负责人伍思磊,他为我们了分享《基于云原生的作业帮大数据采集体系建设与迁移实践》。本次分享他介绍了数据采集、存储与计算以及数据应用三个主要部分,并重点分享了数据库采集从 Canal 到 Flink CDC 以及日志采集到容器化迁移实践两个具体案例。以下内容为分享整理~
作业帮大数据中台全景介绍
首先,我将介绍作业帮及其大数据中台的全景;其次,我将分享数据采集体系架构升级的思路;接下来,我会分享两个具体案例。数据库采集,从 Canal 到 Flink CDC,以及日志采集到容器化的迁移实践。最后,我将讲述一些关于未来规划的思路。
作业帮是一家致力于在线教育科技的中国公司,通过结合人工智能和大数据技术,为学生提供个性化和高效的学习解决方案。作业帮非常注重数据,在其早期发展阶段就以数据驱动为基础,开发了大量产品。数据在作业帮的数据中台扮演着重要角色。
作业帮大数据中台的全景图,从左到右分为三部分:数据采集、存储与计算,以及数据应用。
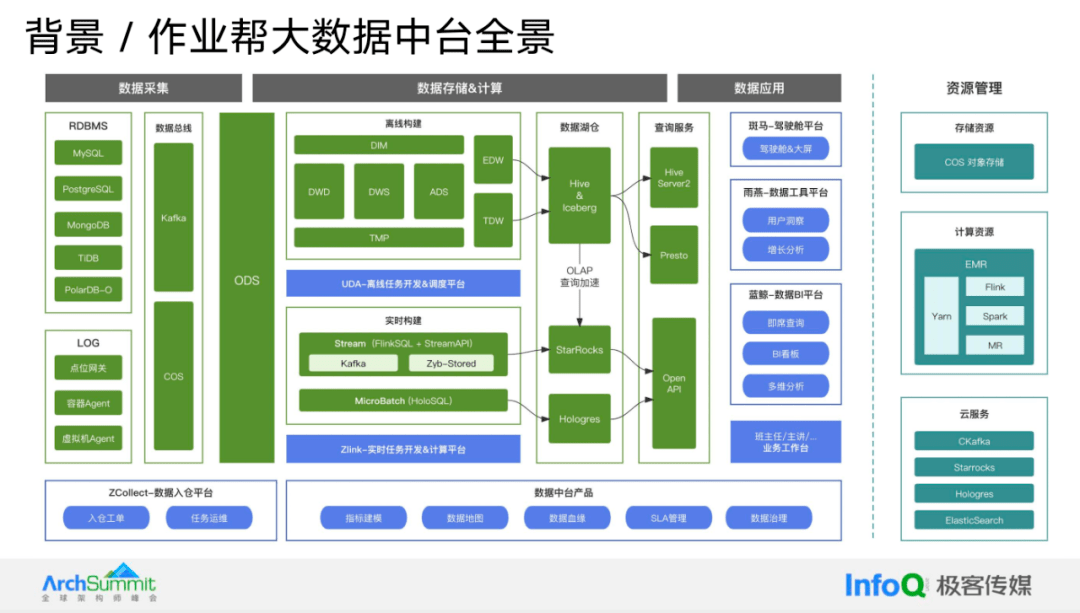
在数据采集部分,作业帮使用两种主要的数据源:关系型数据库(RDBMS)和日志。在数据库方面,我们拥有 MySQL、PG、Mongo、Tidb、PolarDB-O 等多种选项。在日志方面,我们使用了网关容器化的代理和虚拟机代理。数据采集后,进入我们的总线,通过不同的集成方式接入到我们的 ODS 层。
目前,作业帮主要采用两种构建方式:离线构建和实时构建。离线构建是使用 Hive SQL 进行分层建模的经典方式,最终数据会存储到数据仓库中,并通过内部自研的 UDA 离线开发平台和调度平台进行开发工作。
实时构建有两种主要方式,一种是基于流式的实时数仓分层构建方式,另一种是基于强大的计算能力的 Hologres 构建的数仓。实时数仓的每一层都是物理存储,数据最终通过统一的 Open API 接口暴露出来。
在湖仓层,我们拥有 OLAP 数据加速技术,可以将 Hive 中的冷数据集成到 Star Rocks 中,以支持业务需要的秒级查询;在产品层面,主要分为三部分:首先是入仓平台,它负责将数据从各个数据源接入到数据中台体系;中台开发套件则包括指标建模、地图、血缘、SLA 管理治理等;第三部分是数据应用,它包括面向管理者的斑马驾驶舱平台、面向数据运营的雨燕数据工具平台以及面向分析师的蓝鲸数据 BI 平台,共同构成组件。
此外,在在线业务场景工作台资源层面,作业帮目前在存储层面完全接入了 COS,计算层面目前还在使用 EMR,但正在向 K8s 迁移。在云服务方面,我们主要使用了 CKafka、Starrocks、Hologres 和 ES 等服务。
数据采集体系架构升级思路分享
采集体系架构演进历程
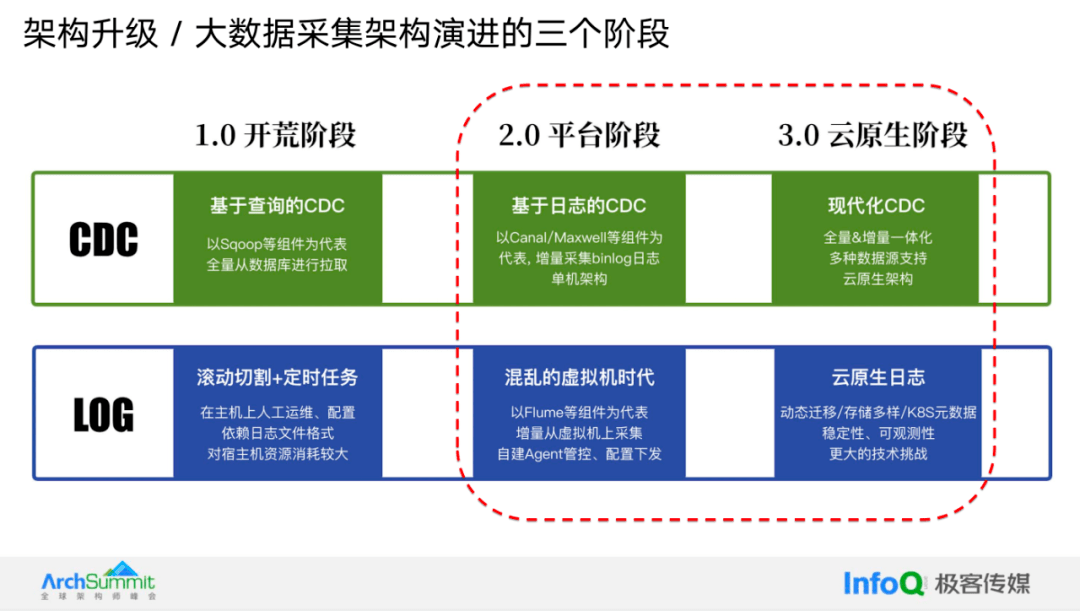
在介绍升级思路之前,让我们先来定义整个大数据采集架构的演进,将其分为三个阶段。
1.0 阶段:
采集主要基于查询构建,使用 Sqoop 等组件进行全量拉取。 日志采集依赖滚动切片和定制任务,在主机上进行人工运维。2.0 阶段:
平台化建设,逐渐采用 Canal 或 Maxwell 等组件实现增量采集。 使用 Flume 等组件进行虚拟机日志采集,需要自建代理进行管理和配置下发。3.0 阶段:
引入 CDC 技术和云原生架构,支持全增量一体化和多种数据源。 基于 K8s 环境进行云原生日志采集,面临技术挑战如动态迁移、多样化存储和 K8s 元数据。在今天的演讲中,将重点讲述作业帮在 2.0-3.0 阶段的升级思路。在 2.0 时代,作业帮的采集架构面临以下问题:
采集架构简单粗暴,扩展性受限,难以集成新的扩展和系统。 采集组件部署在虚拟机上,人工运维稳定性较差。 存在定制化需求,如按表级 / 点位级进行 Kafka 分发,或离线 T+1 数据漂移就绪的需求。 离线数据资源争抢,T+1 快照存在数据延迟。面对这些痛点,作业帮的升级架构目标是:
支持经营决策分析:包括工作台场景、业务分析挖掘场景和管理者驾驶舱场景,需求涵盖实时性、高可用性和数据源多样性。 支持多样性的数据源接入。 确保数据产出的稳定性,采集入仓 SaaS 化,通过租户隔离保证数据产出稳定。 降低成本,实现数据复用和资源弹性扩缩,采用云原生架构。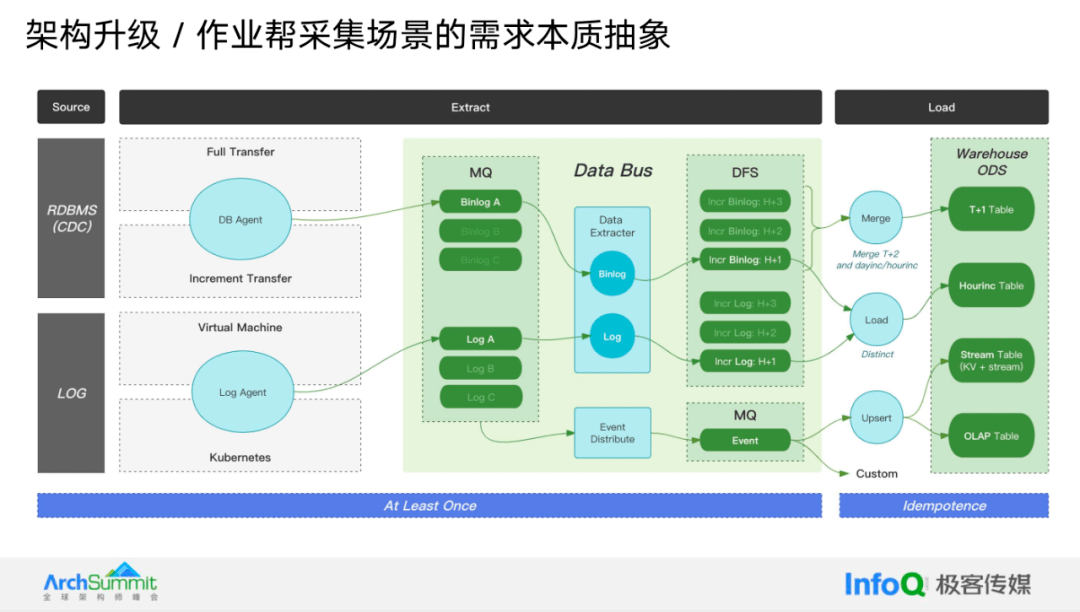
有了整体架构目标后,我们并没有急于进行技术选型的调研,而是对数据采集的需求本质进行进一步抽象。在关系型数据库(RDBMS)层面,我们需要一个数据库代理(DB agent),它能够很好地支持全量和增量场景,并且能够轻松扩展到各种数据源的场景。日志方面,则需要一个 Log Agent,需要能够支持虚拟机和 K8s 的场景,并且可以将数据实时增量地传输到总线中。
我们不能让每个业务方都重复采集数据,这将极大地浪费资源。在总线中,主要体现了数据的复用以及适应下游各种经营场景的能力。总线的核心包含两个关键能力:数据的 Extractor 和点位分发。
集成部分实际上由三种原语组成:合并(merge)、加载(load)和更新插入(upsert)。这三种原语实现了整个集成的需求。在这个过程中,我们要求在采集到总线的部分实现至少一次,而在集成部分实现幂等性,以确保数据的一致性。
在最终选定后,我们使用 Flink CDC 作为数据库代理组件。这个组件包含两部分功能:全增量的一体化组件和一个有界的批处理任务。第二个变化是我们将不再支持虚拟机(VM)侧的数据采集。在总线部分,我们基于 Flink 构建了转发、分发和解析组件。最后,在集成部分,我们针对四种不同的 ODS 场景,提供了四套集成方案。
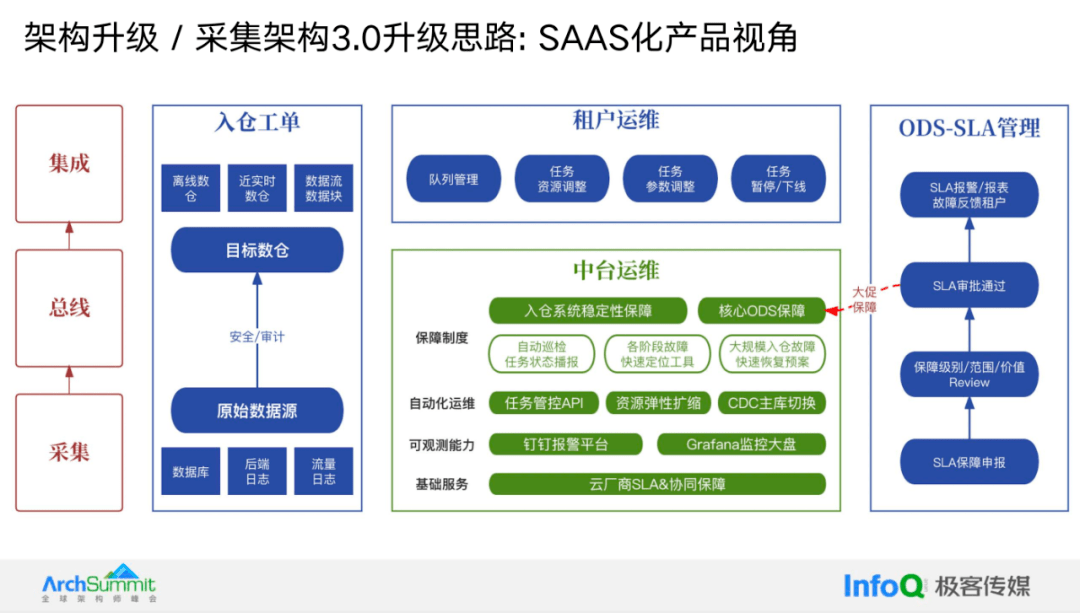
为了更清晰地阐述刚才的升级思路,我们需要换一种视角,以 SaaS 化产品视角来看待这个问题。在产品视角下,仍然有采集、总线和集成这三个阶段,但通过构建入仓平台,并提供入仓工单实体,我们屏蔽了整个入仓过程的复杂性。用户只需明确原始数据源和目标数据源,就能快速进行入仓操作,同时还进行自动化的安全审计。
在运维层面,我们进行了拆解,这主要体现在这三个环节中有一些本质差异。采集和总线本质上仍然是平台级的增量实时采集过程,其核心是保证高可用性。而在集成层面,增加了调度元素,这将涉及更多的资源问题,因此用户需要自行管理这部分,例如针对特定任务,提供自己的队列以及对任务进行资源调优,以确保任务的优先级。最终,我们提供了一个 SLA 管理能力,该 SLA 管理主要针对 ODS 表的粒度,通常由业务方发起并经过审批,然后由下游 BP 的数据团队负责保障 ODS 表的运行。
只有在极个别的场景下,例如大促活动或某些非常关键的保护任务,需要将一些 ODS 表纳入到中台采集体系中,中台将提供大规模入仓的压力测试和预案,以确保这些表的 SLA。
Canal 到 Flink CDC 数据库采集案例分享
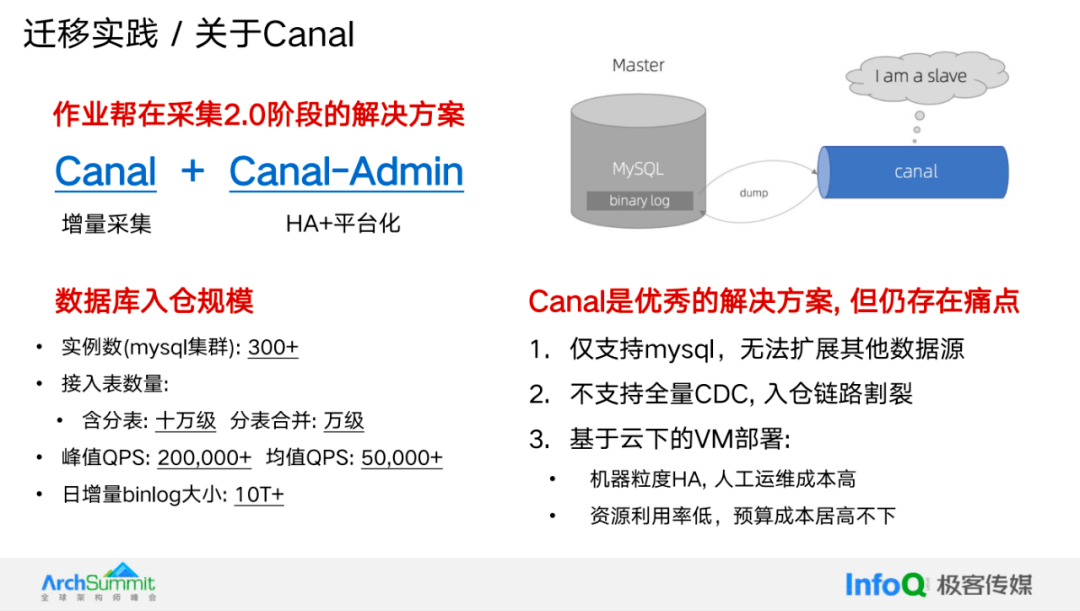
第三部分,我们将提供两个具体实践案例。首先,先来讲一下 Canal。Canal 本身是非常优雅的组件,它通过伪装成从库来消费 MySQL 的 Binlog,实现对 MySQL 的无侵入以及数据同步。然而,Canal 是一个单机架构,因此引入了 Canal Admin 来弥补这一点。通过 Canal Admin,我们可以实现平台化的管控和高可用性。
基于这个方案, 我们接入的 MySQL 集群数量达到了 300+,接入的表数量达到了 10 万级(包括分表,合并后仍然是万级规模)。峰值 QPS 约为 20 万,平均 QPS 为 5 万,每天的增量 Binlog 大小超过 10TB。
虽然 Canal 是很优秀的解决方案,但仍然存在一些痛点。首先,它只支持 MySQL,难以扩展到其他数据源;其次,它不支持全量的 CDC,导致入仓链路存在割裂;第三,对于作业帮这样的场景,Canal 仍然是基于云下虚拟机(VM)部署的,只有机器级别的高可用性,人工运维成本较高,资源利用率非常低。

我们调研了 Debezium 和 Flink CDC 两种技术方案。Debezium 是开源方案,支持多种数据源,但存在全量初始化加锁和单机架构的缺点。我们也调研了基于 Debezium 实现的云厂商 SaaS 采集服务,但它难以与内部平台对接,也难以支持定制化需求。因此,我们选择了 Flink CDC,它支持无锁全量,与内部平台兼容性高。但 Flink CDC 在支持其他数据源方面存在差距,除 MySQL 外,其他数据源的支持相对较少。简而言之,我们最终选择了 Flink CDC 作为技术方案,因为它支持无锁全量,并且与内部平台兼容性高。

接下来是我们 CDC 架构设计的思路。蓝色部分表示一个基于流处理级别的组件,从 CDC 同步到 Kafka。该组件主要解决了三个问题。首先是表的过滤,使用 CDC 的原生能力进行表过滤。第二是解决数据的顺序问题,通过对主键进行分区,重新路由主键,可以在同一个 Kafka 分区内保证数据的有序性;第三则涉及新架构下的 schema 转换,目标是确保转换后的数据与原始架构的 schema 完全相同,以使下游系统无感知。
实现过程中使用的是”at least once”语义,但 CDC 本身无法实现某些核心能力,因此我们在外围做了一些工作。其中包括两个方面,首先是在集群级别挂载了一个心跳表,用于解决低流量下的延迟问题。当一个集群没有流量时,有心跳数据到达时,可以保持下游数据的完整性,以确保某些标记或其他场景能够正常工作。当主库发生故障,发生主从切换时,CDC 无法正常工作。为了解决这个问题,我们设定了一个定时任务,定期扫描主库是否发生切换。如果发生切换,就修改 CDC 的配置,并重新启动任务来实现调度。
在 CDC 的迁移场景中,面临一个挑战:需要将大规模的表从原有架构迁移到 CDC,同时保证用户对这个过程无感知。技术上的挑战有两个方面。首先,我们需要确保 Canal 和 Flink CDC 的输出在数据量和一致性方面完全相同;第二,我们需要尽量无缝地迁移任务,以确保数据不丢失。
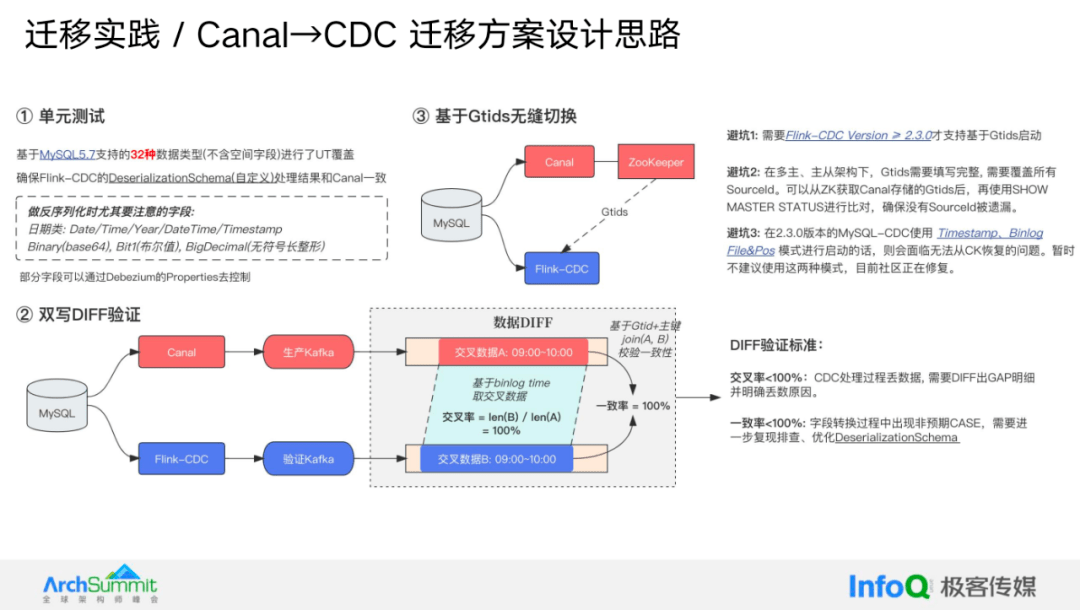
为了解决这个问题,我们实行了迁移方案,总共分为三个部分。
第一部分是构建 UnitTest,对 MySQL 5.7 支持的 32 种数据类型进行全面的 UT 覆盖测试,验证整个 Schema 转换和 Canal 的数据处理结果完全一致。然而,仅仅进行 UT 测试是不够的,所以我们还进行了一层兜底措施,即进行了双写的差异验证。在保持原有 Canal 条链路不变的情况下,我们额外搭建了一条 Flink CDC 的验证链路,使用同一个数据源进行消费。然后进行一次数据 DIFF,比如对比 9 点到 10 点的数据。
在 DIFF 完成后,核心指标是交叉率和一致率。交叉率指的是在相同的时间范围内,数据是否完全交叉匹配;一致率指的是匹配上的数据,例如 before、after、payload 字段是否完全一致。最终,我们需要确保每个数据源都经历了这样的双写流程,交叉率和一致率都达到 100% 才能进行切换。
最后,关于切换,由于使用的 MySQL 完全基于 GTID 进行操作,因此可以基于 GTID 实现优雅的无缝切换。在切换过程中,我们会将 GTID 传递到 ZK,然后关闭配置。当任务启动时,基于 GTID 进行平稳的迁移,使数据能够无缝切换。
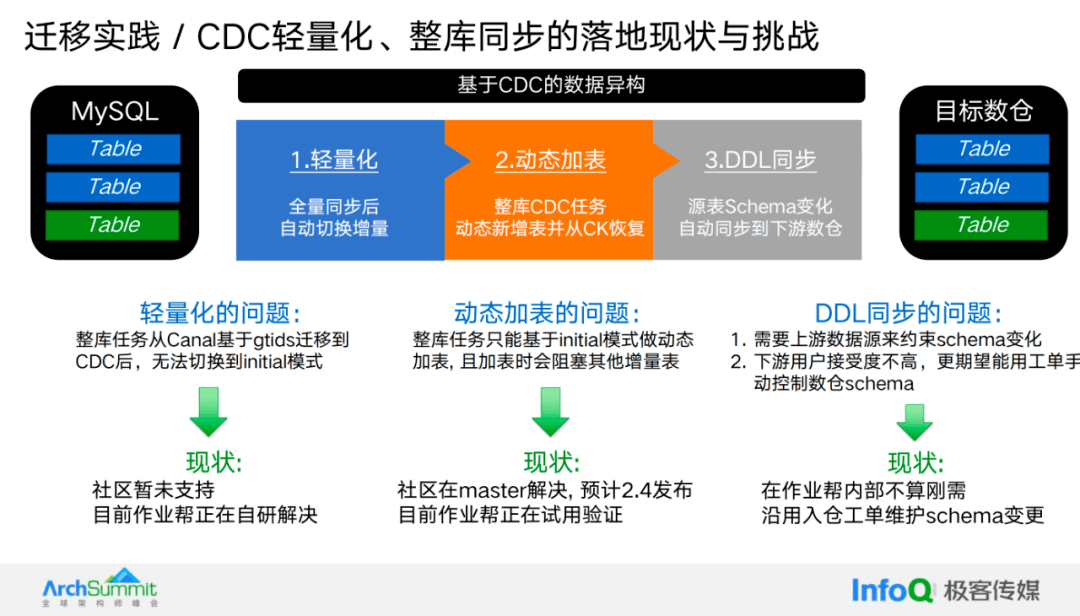
在轻量化和整库同步方面,遇到了一些挑战。首先是轻量化,它指的是全量同步后能够自动切换到增量同步的模式,这是 CDC 的推荐启动模式。然而,我们已有的任务是从其他工具迁移而来,启动模式是基于 GTID 的特殊偏移量。这导致新增的表只能从增量进行消费,无法进行初始化;其次的挑战是动态加表,即在 CDC 任务运行后能够动态修改配置并添加新表,并且能够正常从 Checkpoint 恢复。目前我们的任务只能基于 Initial 模式进行动态加表,不支持 Latest 模式,并且在加表时存在一个缺陷,即新表会进行初始化,会重新拉取大量数据,并导致其他表无法进行增量同步。在作业帮已经修复了这个问题,并正在进行试用。
另外一个问题是 DDL 同步,即当原始表的 schema 发生变化时,能否自动同步到下游数据仓库。这个问题实际上需要依赖上游数据源的 schema 约束才能实现。如果上游数据源的 schema 变化频繁且无法控制,就难以实现自动同步。在最理想的情况下,上游数据库的字段只允许增加,不允许修改或删除,这样下游就可以做到可控。然而,目前我们的下游用户更希望能够手动控制数据仓库的 Schema,而不希望动态变化。因此,目前我们仍然在使用工单手动维护 Schema。
另外我们进行了摸底压测中,我们使用了相同的 MySQL 集群、Binlog 以及下游相同的 Kafka。在这个测试中,我们发现 CDC 的性能比 Canal 要高约 32%。然而,这只是在特定集群环境下的结果,并不是严格的性能测试。此外,性能还取决于使用的版本,我们目前使用的是较旧的版本,而后续版本已经进行了优化,性能可能会有所提升。
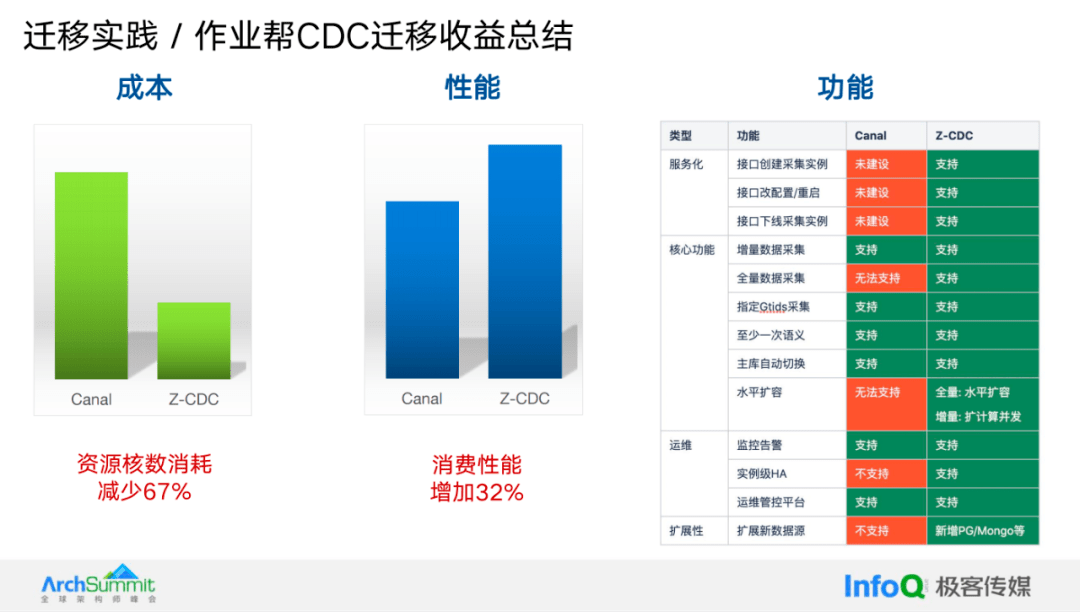
最后,让我们总结一下 CDC 项目的迁移收益。在成本方面,切换到 CDC 后,通过将处理从虚拟机迁移到基于容器的部署,有效减少了资源浪费。
具体而言,资源消耗减少了 67%,性能提升了约 32%;功能层面的收益是最显著的。我们实现了全面的服务化,支持增量和全量采集、水平扩容以及实例级的高可用性。此外,在新的数据源扩展方面,我们可以扩展到更多像 PG/Mongo 这样的数据源。
日志采集到容器化迁移实践案例分享
现在讲述第二个案例——数据采集体系,在日志采集方面,我们从虚拟机迁移到容器化的实践。作业帮接入的日志数据源可能涉及数千家,每天可能达到数十亿条日志,峰值 CPS 可能达到数百万。过去,架构完全基于虚拟机,分为两种场景:流量埋点和后端服务日志。流量埋点通常通过 SDK 打到流量网关上了;日志按小时切割,并由 Flume 进行采集。
需要强调的是,由于我们将 AD(应用部署)与虚拟机绑定在一起,所以围绕它构建了一个重要的管理服务来进行控制。因此,当虚拟机发生变化时,我们需要感知并进行配置下发、心跳控制等一系列能力。此外,在下游场景中,我们不希望在某个小时的数据尚未完全采集时,就让下游访问到。因此,引入了一个重要的组件,即日志 Sink 管理器,确保在完全采集完一个小时的数据后才将其暴露给下游可用,这在我们的场景中称为”Done 标记”。

在虚机采集场景中存在几个痛点。首先,流量网关部署在虚机上,导致运维成本高且不稳定。随着后端服务陆续上云,现有的采集接入体系无法满足淡标记需求,因为之前是将虚机与采集绑定,维护成本大且稳定性差。这带来了两个核心技术挑战:流量网关如何上云以及在 K8s 下如何支持 Done 标记需求。
首先看一下上云思路。数据通过 SDK 传入后,由负载均衡器(LB)进行路由,直接进入虚机集群进行采集。然而,在迁移到 K8s 时,面临一个问题:通常情况下,流量应该进入 K8s Ingress 网关,但由于流量非常大(数百万 QPS),并且网关中的大部分功能都用不到,因此需要绕开流量网关,直接将数据引流到 Pod 中。这增加了一些运维成本,但能够降低资源开销。
当数据进入 Pod 后,数据不再按小时切割,可能会落盘到宿主机上,并按照大小进行切割。这对于后续实现 Done 标记需求提出了挑战。
Done 标记需求是一个核心诉求,数据在 Pod 层进行了分发,以确保数据在 Kafka 分区内的 Pod 中有序。在 Flink 消费层和存储层,我们通过维护每小时的最大时间戳状态来判断是否标记为断。当某个 Pod 的数据在当前小时的最大时间戳超过当前小时时,可以将该 Pod 标记为断。当所有与该日志对应的 Pod 都标记为断时,可以向下游发送断消息,确保数据已就绪。由于 Pod 可以动态扩缩,需要获取广播变量来获取具体的 Pod 数量和规格。当 Pod 下线时,需要监听 Pod 的下线日志,立即将下线的 Pod 标记为断,以确保一致性。
对于低流量场景,某些 Pod 可能长时间没有数据采集,需要使用心跳探活的方式进行保证下游数据工作。
迁移方案类似于 CDC 的思路,采用双写验证方式,通过流量复制进行数据双写,只有通过 DIFF 的数据才能进行迁移切换。切换过程需要确保对下游用户无感知。由于切换中涉及到一些业务场景,整个迁移方案比较复杂,具体细节略过。
最后来看迁移的收益情况。在成本方面,通过根据流量潮汐动态扩缩 Pod,每天的流量高峰只发生在晚上,白天流量较小,因此整体资源消耗减少了 54%;在运维层面,由于实现了 K8s 化,不再需要专人维护 VM 集群和 Agent,运维人力从 3 人力降低到了 0.5 人力。
未来规划思路展望
作业帮计划在 CDC 轻量化和整库同步方面进一步优化,抽象接入能力以低成本接入更多新的数据源,并进一步增强可观测性,实现全物感知的强大管控能力。
活动推荐 返回搜狐,查看更多
责任编辑:


















暂无评论内容