
1、推荐算法原理(协同过滤)
2、推荐算法建模1、推荐算法原理(协同过滤)?
协同过滤推荐算法分为两类:基于用户的协同过滤算法、基于物品的协同过滤算,简单的说就是:人以类聚,物以群分。分别说明这两类推荐算法的原理和实现方法。
基于用户的协同过滤算法?
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行打分,根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系,在有相同喜好的用户间,实现未购买商品、未查看内容智能推荐
通俗解释:
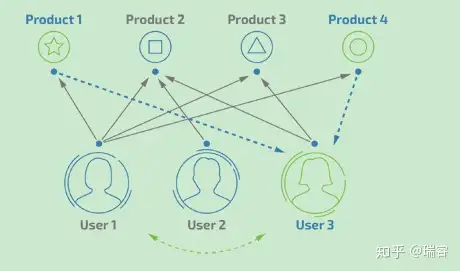
如果user1、user3两个用户都购买了product2、product3产品,并且给出了5星的好评。那么user1、user3就属于同一类用户。可以将user1购买的product1、product4也推荐给用户user3
基于物品的协同过滤算法?
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。
通俗解释:
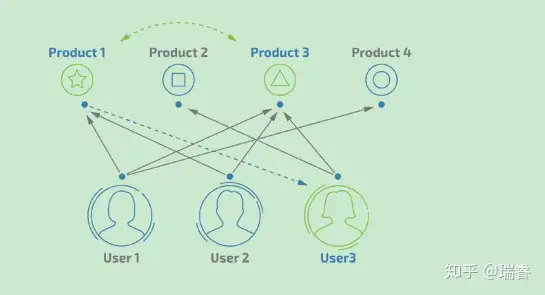
如果用户user1同时购买了product1和product3,那么说明product1和product3的相关度较高,当用户user2也购买了product1时,可以推断他也有可能购买product3的需求。
推荐算法实现?
推荐步骤:
计算similarity(用户间或物品间相似度):通常采用pearson相关系数或余弦相似度。计算prediction(目标用户未购买物品对目标用户的吸引力):目标用户对未购买商品的预测评分。计算recommendation:向目标用户推荐前K个吸引力最大的物品。输入
协同过滤方法以用户-物品评分矩阵作为输入
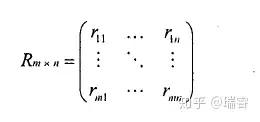
评分矩阵中的行代表了用户向量,列代表了物品向量,计算用户间的相似度是计算评分矩阵中行向量的相似度
计算相似度:
余弦相似度(cos)或皮尔逊相关系数(pearson)进行用户、物品相似度计算
余弦相似度
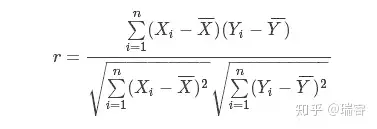
2、推荐算法建模
输入用户评分矩阵如下:
import numpy as np
from colorama import Fore
import pandas as pd
users = [“小张”, “小王”, “小李”, “小招”, “小冯”]
movies = [“电影1”, “电影2”, “电影3”, “电影4”, “电影5”, “电影6”, “电影7”]
allUserMovieStarList = [
[3, 1, 4, 4, 1, 0, 0],
[0, 5, 1, 0, 0, 4, 0],
[1, 0, 5, 4, 3, 5, 2],
[3, 1, 4, 3, 5, 0, 0],
[5, 2, 0, 1, 0, 5, 5]]
df = pd.DataFrame(allUserMovieStarList,columns=movies,index=users)
print(df)

欧氏距离计算两个用户之间的相似度:
def sim_distancec(person1: str, person2: str) -> str:
“””
欧氏距离计算两个用户之间的相似度
:param person1:
:param person2:
:return:
“””
index_user1 = users.index(person1)
index_user2 = users.index(person2)
score_user1 = allUserMovieStarList[index_user1]
score_user2 = allUserMovieStarList[index_user2]
distance = np.sqrt(((np.array(score_user1) – np.array(score_user2)) ** 2).sum())
return distance
def cal_all_user_distance(person: str, order: int = 1) -> list:
“””
计算person和其他用户的相似度 ,并返回有序列表
:param person:
:param order: 1为升序,0为降序 默认为1
:return:list
“””
all_user_sim = [(sim_distancec(u, person), users.index(u)) for u in users if u != person]
all_user_sim.sort()
if order == 1: return all_user_sim
all_user_sim.reverse()
return all_user_sim
def cal_movie_recommend(person: str):
“””
取与person相似的前两个用户
相似度*
:param person:
:return:
“””
users_sim = cal_all_user_distance(person)[0:2]
# print(len(users_sim))
sumRate = 0
tempRate = 0
recommendMovies = []
for i in range(0, len(movies)):
tempRate = allUserMovieStarList[users_sim[0][1]][i] * users_sim[0][0] + allUserMovieStarList[users_sim[1][1]][
i] * users_sim[1][0]
sumRate += tempRate
recommendMovies.append(tempRate)
# print(recommendMovies)
temp = enumerate(recommendMovies)
t = sorted(temp, key=lambda index: index[1])
avg = sumRate / len(movies)
targetMoviesIndex = [i for i, v in t if v > avg]
# print(targetMoviesIndex)
targetMovies = [movies[t] for t in targetMoviesIndex if allUserMovieStarList[users.index(person)][t] == 0]
targetMovies.sort()
return targetMovies
# print(cal_all_user_distance(小张))
def main(username: str):
print(Fore.GREEN, username, Fore.RESET)
print(推荐电影列表:, cal_movie_recommend(username))
if __name__ == __main__:
main(“小张”)
main(“小冯”)
main(“小王”)

THE END

















暂无评论内容