
【本文专栏于[头条号]、[CSDN]同步发布,可关注同名账号订阅相关文章,每周固定更新】
对于大多数刚入门k8s的朋友们来说,k8s强大容器编排功能能让我们把更多的目光聚焦在应用级的系统架构设计上。对于硬件资源充裕的团队,甚至存在资源不够机器来凑的情况。但kubernetes毕竟无法完全适配实际的使用场景,默认的配置只能提供最最初级的资源管理,如何让kubernetes更好的适配我们的物理环境?如何利用kubernetes帮助我们最大可能的规避资源所带来的风险?本文将结合实例针对kubernetes中的资源管理进行详细的介绍。
一次集群雪崩引发的思考
至今还清晰的记得,那是一个下雨的深夜。
熟睡的我突然被一阵报警短信惊醒。
迷迷糊糊一瞟。是节点notReady报警。非常不情愿的爬起来查看集群状态,心想集群机器够用,肯定扛得住。
然而现实深深地在我脸上拍了两下。
集群中多个大应用同时出现慢查询query,导致应用处理耗时过高,32核的机器load直线飙升。同时Pod压榨到了kubelet组件的资源,导致kubelet与APIServer的心跳断了,超过阈值节点Not Ready。
接着,该节点的Pod会在其他节点上迅速扩散,大量的Pod重建接连压垮了多个节点,进而节点Not Ready如潮水般扩散,俗称集群雪崩。集群内的Nodes逐个的Not Ready了,后果非常严重。后续组内同事迅速将流量切到备用集群,尽最大可能挽回损失。
经过这一劫,让我深深感到资源管理的重要性,对集群的资源管理进行一次整改。先来看看kubernetes为我们提供了怎么的管理方式。
先抛两张Kubernetes基础组件架构图:
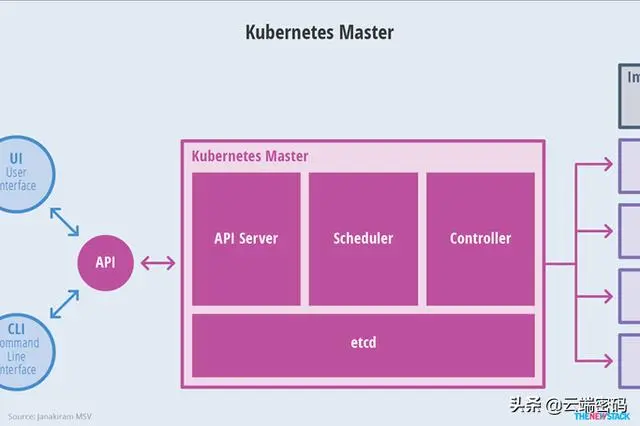
K8S Master
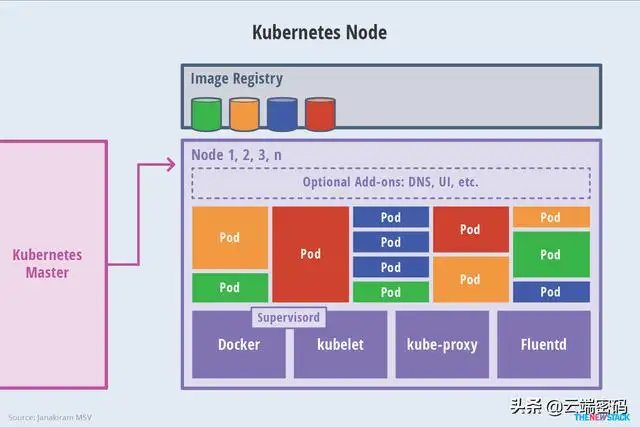
K8S node
Master部分,由于在物理部署时,Master并不承载具体的业务,且单独部署在物理机上,因此这一块的系统资源使用率较低。这里不做深入讨论。
这里主要对Node节点进行深入探讨。Node节点的资源控制主要由Kubelet进行配置。Kubelet中Node Allocatable提供了为系统进程预留计算资源的配置方法,从而在节点出现资源匮乏时也能保证k8s组件及System有足够的资源。
来看Node Allocatable提供的资源管理项。
Node Capacity是Node的所有硬件资源
kube-reserved是给kube组件预留的资源
system-reserved是给System进程预留的资源
eviction-threshold是kubelet eviction的阈值设定
allocatable才是真正scheduler调度Pod时的参考值(保证Node上所有Pods的request resource不超过Allocatable)
上面这个层级结构用一条公式概括就是:
我们该如何设置?
系统级配置
1,–enforce-node-allocatable
–enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
这个选项是默认开启的,当Pod的资源使用量超过了Allocatable,pod将被驱逐。
2,–cgroups-per-qos
该选项默认开启,开启后,kubelet会管理所以带负载的Pod的cgroups。
3,–cgroup-driver
配置cgroups驱动,该选项可选的参数是systemd和cgroupfs。具体的配置取决于相关容器运行时(container runtime)的配置。例如如果操作员使用 docker 运行时提供的 cgroup 驱动时,必须配置 kubelet 使用 systemd cgroup 驱动
4,–kube-reserved
用于配置为kube组件(kubelet,kube-proxy,dockerd等)预留的资源量,比如—kube-reserved=cpu=1000m,memory=8Gi,ephemeral-storage=16Gi。
5,–kube-reserved-cgroup
如果你设置了–kube-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为kube-reserved-cgroup=/kubelet.service 。
6,–system-reserved
用于配置为System进程预留的资源量,比如—system-reserved=cpu=500m,memory=4Gi,ephemeral-storage=4Gi。
7,–system-reserved-cgroup
如果你设置了–system-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为system-reserved-cgroup=/system.slice。
8,–eviction-hard
用来配置kubelet的hard eviction条件,只支持memory和ephemeral-storage两种不可压缩资源。当出现MemoryPressure时,Scheduler不会调度新的Best-Effort QoS Pods到此节点。当出现DiskPressure时,Scheduler不会调度任何新Pods到此节点。
举个官方例子趁热打铁
节点拥有 32Gi 内存,16 核 CPU 和 100Gi 存储
在这个场景下,Allocatable 将会是 14.5 CPUs、28.5Gi 内存以及 98Gi 存储。调度器保证这个节点上的所有 pod 请求的内存总量不超过 28.5Gi,存储不超过 88Gi。当 pod 的内存使用总量超过 28.5Gi 或者磁盘使用总量超过 88Gi 时,Kubelet 将会驱逐它们。如果节点上的所有进程都尽可能多的使用 CPU,则 pod 加起来不能使用超过 14.5 CPUs 的资源。
当没有执行 kube-reserved 和/或 system-reserved 且系统守护进程使用量超过其预留时,如果节点内存用量高于 31.5Gi 或存储大于 90Gi,kubelet 将会驱逐 pod。
Pod级配置
配置完系统级的资源管理,别忘了还有pod级资源。
1, Request和Limit限制
Kubernetes提供了针对memory和CPU的容器级的资源限制。每个资源又分为request和limit两种配置项。
Request: 容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量>=容器资源请求数时才允许将容器调度到该节点。但Request参数不限制容器的最大可使用资源。
Limit: 容器能使用资源的资源的最大值,设置为0表示使用资源无上限。
Request能够保证Pod有足够的资源来运行,而Limit则是防止某个Pod无限制地使用资源,导致其他Pod崩溃。两者之间必须满足关系: 0<=Request<=Limit<=Infinity (如果Limit为0表示不对资源进行限制,这时可以小于Request)
2, Pod的反亲和力配置
这一配置根据已在节点上运行的pod上的标签来限制pod可以调度到哪些节点,而不是基于节点上的标签。
这一点在往往容易被人忽视,这个选项看起来只是限制Pod的部署方式,但恰恰是这一特性,可以帮你避免了同一个应用的多个副本同时部署在一台节点是。结合我的雪崩例子,集群中的应用均是以多副本的形式部署在集群中的,在正常情况下,pod随机分配到各个node上,同一节点有可能存在同个应用的多个副本。一旦该应用的负载升高,那这个存在多个副本的节点势必受到成倍的负载压力。因此对于多副本的应用,配置反亲和力是非常有必要的。
举个栗子:
这一段使用preferredDuringSchedulingIgnoredDuringExecution,表示如果某个节点已经运行着具有“app=Hot”标签的pod,那该pod将不会优先调度到该节点。
通过对集群进行以上的配置,相信能够为你的集群可用性带来较大的提升。
如果觉得有些收获,记得关注我哟。
















暂无评论内容