
Kubernetes 是一个开源平台,用于自动进行容器编排,即容器化应用程序的部署、扩展和管理。
什么是 KUBERNETES?
Kubernetes 提供了一个框架,用于部署、管理、扩展和切换分布式容器,这些容器是随依赖项和配置打包的微服务。
它建立在 Google 十多年的容器管理系统开发经验基础上,并结合了来自社区的出色想法、模式和实践。
为何选择 KUBERNETES?
软件容器随着 2013 年出现的 Docker 得到了普及,而现在,Moby 也发挥了这一作用。容器镜像会打包整个运行时环境,包括应用程序,以及执行应用程序所需的所有依赖项、库和其他二进制文件以及配置文件。与虚机相比,容器具有相似的资源和隔离优势,但更为轻巧,因为容器将操作系统虚拟化而非采用硬件。容器便于移植,占用空间以及使用的系统资源更少,且几秒钟内即可加快运行。容器还可提高开发者的效率。DevOps 团队无需再等待操作系统来配置计算机,他们可以快速将应用程序打包到容器中并部署。
![图片[1]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-9141b80015d604beb95501400a05d4a3_720w.webp)
得益于这些优势,容器立即受到开发者的青睐,并迅速成为云应用程序部署的热门选择。容器的普及意味着一些组织很快会运行成千上万个容器,因此需要实现管理自动化。Kubernetes 简化了容器管理,因此大受欢迎,并通过进一步支持微服务架构使容器成为主流,该架构促进了云原生应用程序的快速交付和可扩展编排。
云原生计算基金会 (Cloud Native Computing Foundation) 成立于 2015 年,是 Linux 基金会的一个项目,旨在推动云原生技术的采用。其中包括容器、服务网格、微服务、不可变基础设施以及声明性 API,并围绕一套通用标准使开发者保持一致。CNCF 为许多增长快速的开源项目(包括 Kubernetes)提供了供应商中性平台。该团队的工作有助于防止 Kubernetes 代码库出现分叉。因此,各大计算平台和云提供商现在都支持相同的 Kubernetes 代码库。虽然已经出现了 Kubernetes 的品牌版本(如 Red Hat OpenShift 或 Amazon Elastic Kubernetes Service),但其底层代码是相同的。
KUBERNETES 的工作原理是什么?
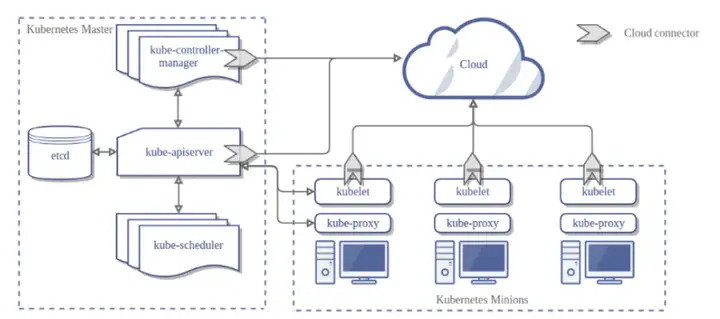
Kubernetes 引入了一个分组概念(称为“POD”),允许多个容器在主机上运行,并共享资源,而不会发生冲突。POD 可用于定义共享服务(如目录、IP 地址或存储),并公开至 POD 中的所有容器。这使得应用程序内的服务能够容器化并一起运行,因为每个容器都与主应用程序紧密相连。
![图片[2]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic1.zhimg.com/80/v2-0d363686e35f9d827368ae33d1a708d4_720w.webp)
节点代理称为 kubelet,用于管理 POD、容器和图像。Kubernetes 控制器管理 POD 集群,并确保分配充足资源,以实现所需的可扩展性和性能级别。
![图片[3]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-64707297eccd72808475992195566816_720w.webp)
Kubernetes 提供各种有用服务,特别是在集群环境中。它实现了服务发现和负载均衡的自动化,自动安装存储系统,并自动推广和回退,以达到指定的预期状态。它还会监控容器运行状况、重启出现故障的容器,并启用密码和密钥等敏感信息以安全存储在容器中。
这简化了机器和服务管理,使单个管理员能够管理同时运行的数千个容器。Kubernetes 还允许跨现场部署到公共或私有云,以及介于两者之间的混合部署的编制。
Kubernetes 因其作为一个支持混合云计算平台的承诺引起了很多关注。由于每个物理和虚拟环境中的代码库都相同,因此从理论上讲,容器化应用程序可以在支持 Kubernetes 的任何平台上运行。业界仍在持续讨论混合架构的优点。支持者表示,这种方法可以避免出现锁定问题,而反对者则认为,在可移植性方面做出的妥协在于,开发者只能使用一系列有限的开源技术,无法利用品牌云和本地平台上的全部服务功能。
KUBERNETES 用例
如上所述,混合和多云部署是 Kubernetes 的一个理想用例,因为应用程序无需与底层平台绑定。Kubernetes 负责处理资源分配并监控容器运行状况,以确保根据需要提供服务。
Kubernetes 还非常适合可用性至关重要的环境,因为编排器可以抵御故障实例、端口冲突和资源瓶颈等问题。
容器是一种用于无服务器计算的基础技术,在这种计算中,应用程序由活跃的服务构建,这些服务仅针对该应用程序的需要执行函数。无服务器计算有点用词不当,因为容器必须在服务器上运行。但目标是将虚机封装到容器中,以尽可能减少调配虚机所需的成本和时间,这些容器几毫秒内即可启动,由 Kubernetes 管理。
Kubernetes 还有一个称为命名空间的功能,指一个集群内的虚拟集群。允许运营和开发团队共享同一组物理机,并访问相同服务,而不会造成冲突。
KUBERNETES 的重要意义
| 数据科学家
数据科学的挑战之一是在可复制的环境中创建可重复的实验,并能够跟踪和监控生产中的指标。容器能够创建具有多个协调阶段的可重复流程,这些流程以可复制的方式协同工作,用于处理、特征提取和测试。
Kubernetes 中的声明性配置描述了服务之间的关系。微服务架构使调试变得更容易,并改善了数据科学团队成员之间的协作。数据科学家还可以利用 BinderHub 等扩展程序,从存储库中构建和注册容器镜像,并将它们发布为其他用户可交互使用的共享笔记本。
Kubeflow 等扩展程序简化了在 Kubernetes 中设置和维护机器学习工作流程和管线的过程。编排器具有可移植性优势,让数据科学家可以在笔记本电脑上进行开发,并随时随地进行部署。
| Devops
数据工程师很难将机器学习模型投入生产。他们花时间编辑配置文件、分配服务器资源,还要担心如何在不导致项目崩溃的情况下扩展模型并整合 GPU。容器生态系统引入了许多工具,旨在简化数据工程师的工作。
例如,Istio 是一个可配置的开源服务网格层,可用于轻松创建一个具备自动化负载均衡、服务到服务身份验证以及监控的已部署服务网络,且无需对服务代码做任何更改。它可精细控制流量行为、丰富的路由规则、重试、故障转移和故障注入,以及用于访问控制、速率限制和配额的可插入策略层和配置 API。
Kubernetes 生态系统借助此类专用工具继续发展,使服务器配置隐形,允许数据工程师可视化依赖项,从而简化配置和故障排除。
为何 KUBERNETES 在 GPU 上表现更出色
Kubernetes 包括对 GPU 的支持,这使得配置和使用 GPU 资源来加速数据科学、机器学习和深度学习等工作负载变得容易。设备插件允许 POD 访问 GPU 等专用硬件功能,并作为可调度资源公开。
随着 AI 应用程序和服务的不断增加以及公有云中 GPU 的全面发售,Kubernetes 需要具备 GPU 感知能力。NVIDIA 一直在稳步构建其软件库,以优化在容器环境中使用的 GPU。例如,NVIDIA GPU 上的 Kubernetes 支持多云 GPU 集群通过跨多节点集群 GPU 加速容器的自动化部署、维护、调度和操作实现无缝扩展。
![图片[4]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-f1cb94116f63bc406fca072c5d1bf736_720w.webp)
GPU 上的 Kubernetes NVIDIA 具有以下主要特性:
借助 NVIDIA 设备插件,在 Kubernetes 中启用 GPU 支持指定 GPU 属性(例如 GPU 类型和内存需求),以便在异构 GPU 群集中进行部署借助 NVIDIA DCGM、Prometheus 和 Grafana 的集成 GPU 监控堆栈,允许对 GPU 指标和运行状况进行可视化和监控支持多个基础容器运行时,例如 Docker 和 CRI-ONVIDIA DGX™ 系统提供官方支持
NVIDIA EGX™ 堆栈是一款可扩展的原生云软件堆栈,可实现由 Kubernetes 管理的容器化加速 AI 计算。借助 NVIDIA EGX 堆栈,组织可以在几分钟内轻松部署经过更新的 AI 容器。
![图片[5]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-8f3fcaa599b255cef09b94cd38f749e2_720w.webp)
但是,Kubernetes 并不是什么灵丹妙药。它为资源发现和管理提供了良好的 API,但其并非简化资源使用的全部解决方案。因此,NVIDIA 开发了 Triton,这是一个开源推理服务平台,允许用户在任何 GPU 或基于 CPU 的接口上部署 AI 训练模型。在 Kubernetes 环境中运行 Triton,可以完全从软件中提取出硬件。在这种情况下,Kubernetes 充当 Triton 运行的基础。Triton 负责提取节点内的硬件,而 Kubernetes 负责编排集群,使其能够更有效地向外扩展。
![图片[6]-NVIDIA 大讲堂 | 什么是 KUBERNETES?-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-e2a26a92671f35c642443f727d681669_720w.webp)
GPU 硬件中的 KUBERNETES
除了软件之外,NVIDIA 已采取措施定制其硬件,以用于虚拟化环境。不过,这并非 Kubernetes 所特有。随着公司推出基于 Ampere™ 的 A100 企业级 GPU 和 DGX A100 服务器,NVIDIA 还推出了多实例 GPU (MIG)。MIG 允许将单个 A100 GPU 分割为七个小 GPU,类似于将 CPU 分割成多个单独核心。允许用户使用 Kubernetes 等容器运行时以更精确的粒度自动扩展其应用程序。
在 MIG 推出之前,GPU 加速 Kubernetes 集群中的每个节点都需要自己的专用 GPU。有了 MIG,单个 NVIDIA A100(DGX A100 中有 8 个)现在可以支持多达 7 个小节点。这使得应用程序和资源可以实现更大规模的线性扩展。
随着 AI 服务成为 GPU 加速工作负载,而这正处于成功前的拐点,GPU 将开始进入 Kubernetes 的主流。随着形势发展,人们会把 GPU 加速视为一个快速或高效的按钮,而不必考虑 GPU 开发或编程。

















暂无评论内容